Week 1, Session 3 — Data types, tidy data, accuracy and precision
Course 1 — #courses
3. Execution
Reshape to a long form where each row is one reading.
# A tibble: 6 × 5
id sex visit reading sbp
<chr> <chr> <fct> <int> <dbl>
1 P01 F V1 1 155.
2 P01 F V1 2 116.
3 P01 F V1 3 145.
4 P01 F V2 1 143.
5 P01 F V2 2 136.
6 P01 F V2 3 138.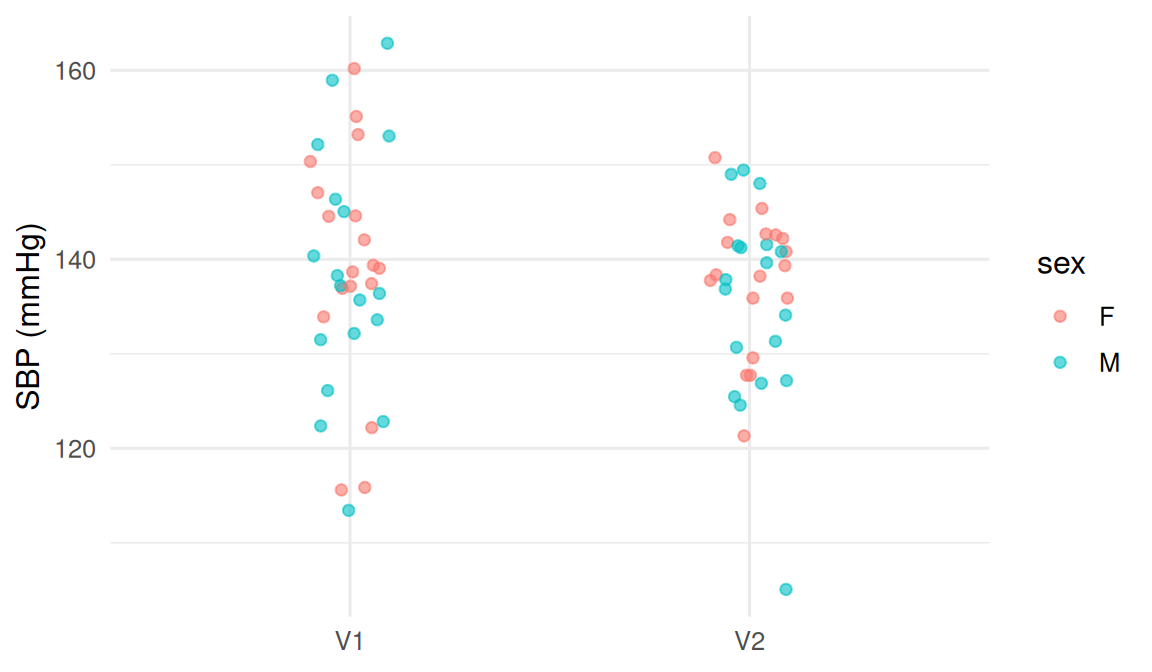
The long format makes it trivial to summarise by visit, by patient, or by visit-and-patient. The same plot in wide format would require custom code for each visit column.
# A tibble: 6 × 4
id sex V1 V2
<chr> <chr> <dbl> <dbl>
1 P01 F 138. 139.
2 P02 F 146. 137.
3 P03 F 149. 136.
4 P04 F 132. 139.
5 P05 M 145. 119.
6 P06 M 146. 140.4. Check
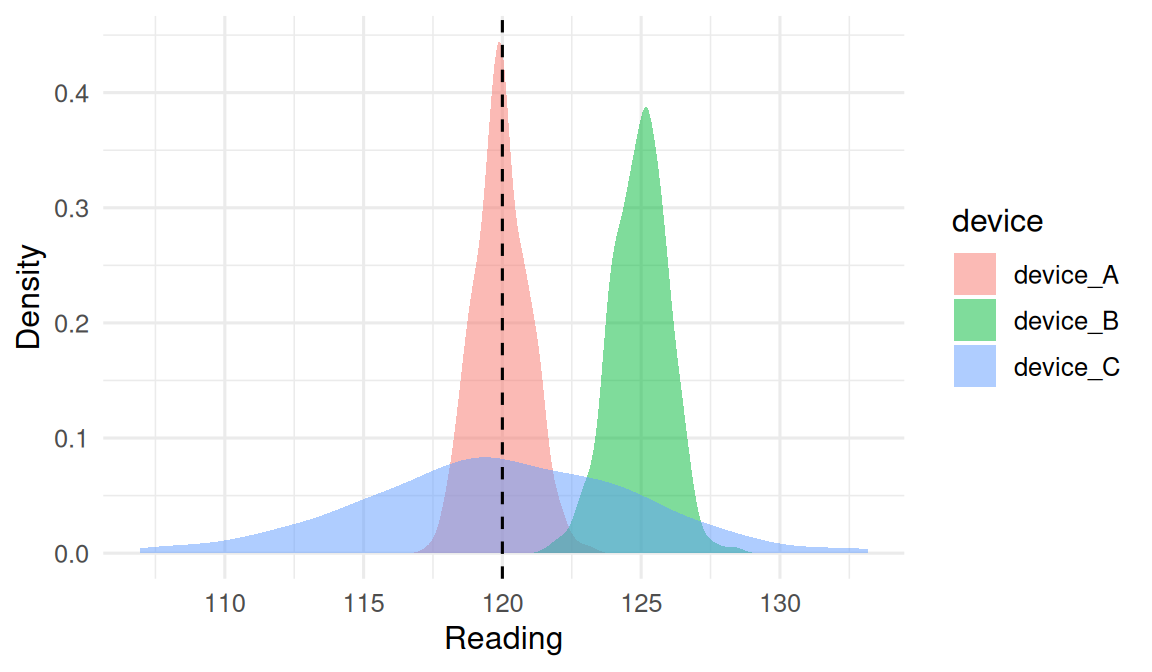
Simulate an instrument with a known truth (say, a calibrated reference of 120) and compare three candidate devices with different accuracy/precision profiles.
truth <- 120
n <- 500
devices <- tibble(
device_A = rnorm(n, mean = 120, sd = 1), # accurate & precise
device_B = rnorm(n, mean = 125, sd = 1), # precise, biased
device_C = rnorm(n, mean = 120, sd = 5) # accurate on average, imprecise
) |>
pivot_longer(everything(), names_to = "device", values_to = "reading")
summary_table <- devices |>
group_by(device) |>
summarise(mean = mean(reading),
sd = sd(reading),
bias = mean(reading) - truth,
rmse = sqrt(mean((reading - truth)^2)))
summary_table# A tibble: 3 × 5
device mean sd bias rmse
<chr> <dbl> <dbl> <dbl> <dbl>
1 device_A 120. 0.974 -0.0280 0.974
2 device_B 125. 1.02 4.95 5.06
3 device_C 120. 4.83 -0.0819 4.83