Week 2, Session 2 — Probability, conditional probability, Bayes’ theorem
Course 1 — #courses
2. Visualise
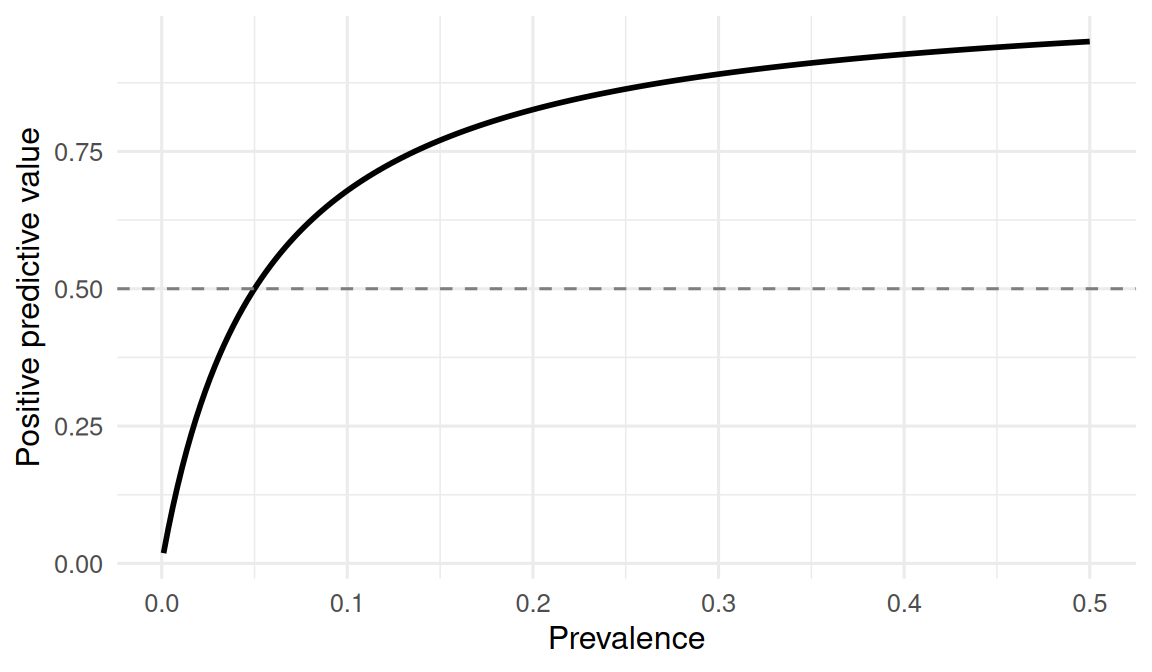
Simulate a population of 100,000 people. Prevalence of disease = 1%. Test sensitivity = 95%. Test specificity = 95%.
as_tibble(tab) |>
mutate(disease = recode(disease, `0` = "no disease", `1` = "disease"),
test = recode(test, `0` = "neg", `1` = "pos")) |>
ggplot(aes(test, disease, fill = n)) +
geom_tile() +
geom_text(aes(label = n), colour = "white") +
scale_fill_viridis_c() +
labs(x = "Test result", y = "True state", fill = "Count")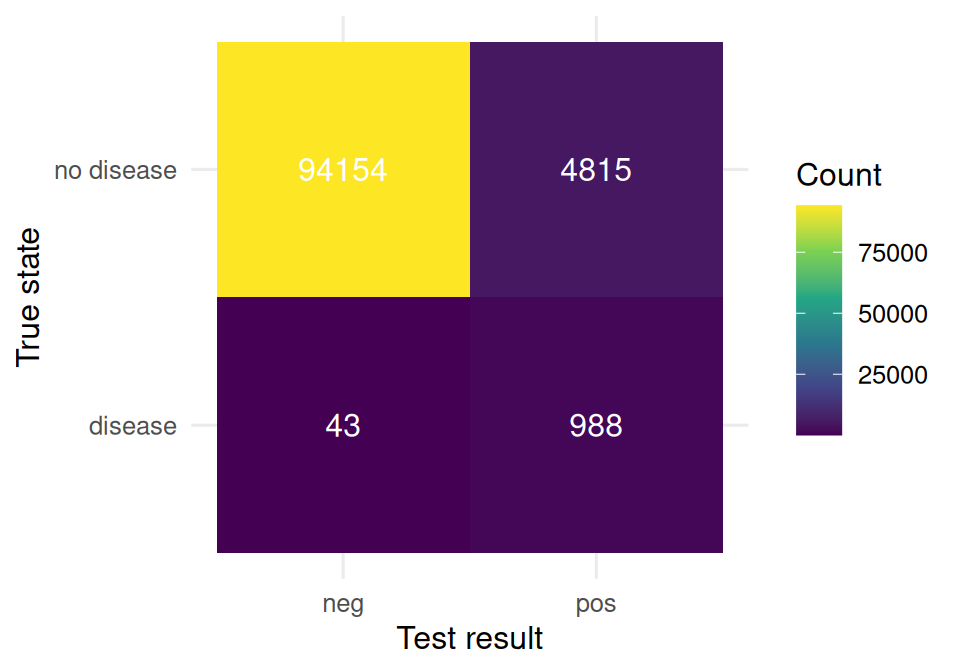
4. Conduct
Apply Bayes’ theorem by hand.
[1] 0.1610169[1] 0.1702568Same quantity, two routes. Bayes is algebra on the marginals; simulation is counting from the table. They must agree, within sampling error.