Week 2, Session 3 — Diagnostic testing: Se, Sp, PPV, NPV, LR
Course 1 — #courses
2. Visualise
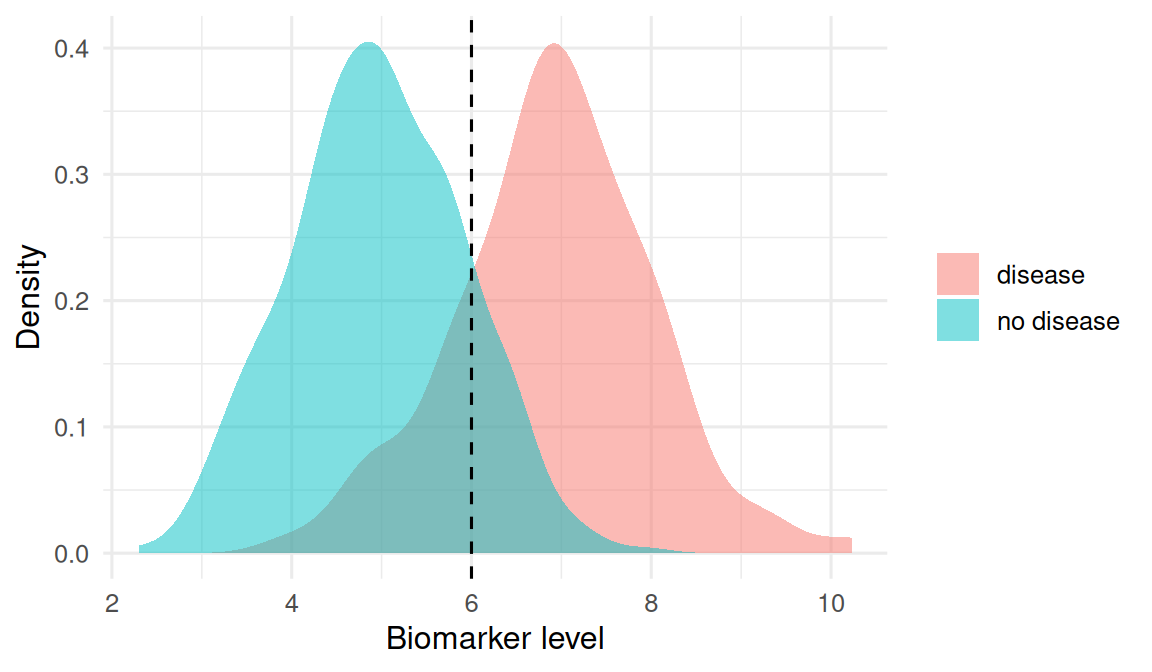
Simulate a biomarker that is higher in diseased cases than in disease-free controls, with overlap.
4. Conduct
TP <- tab["1", "1"]; FN <- tab["1", "0"]
FP <- tab["0", "1"]; TN <- tab["0", "0"]
sens <- TP / (TP + FN)
spec <- TN / (TN + FP)
ppv <- TP / (TP + FP)
npv <- TN / (TN + FN)
lrp <- sens / (1 - spec)
lrn <- (1 - sens) / spec
diag_tbl <- tibble(
quantity = c("Sensitivity", "Specificity",
"PPV", "NPV", "LR+", "LR-"),
value = c(sens, spec, ppv, npv, lrp, lrn)
)
diag_tbl# A tibble: 6 × 2
quantity value
<chr> <dbl>
1 Sensitivity 0.792
2 Specificity 0.867
3 PPV 0.602
4 NPV 0.943
5 LR+ 5.96
6 LR- 0.240Convert pre-test odds to post-test odds with the LR.
pre_prob <- 0.1
pre_odds <- pre_prob / (1 - pre_prob)
post_odds_pos <- pre_odds * lrp
post_prob_pos <- post_odds_pos / (1 + post_odds_pos)
post_odds_neg <- pre_odds * lrn
post_prob_neg <- post_odds_neg / (1 + post_odds_neg)
tibble(
pre_prob,
post_prob_if_positive = post_prob_pos,
post_prob_if_negative = post_prob_neg
)# A tibble: 1 × 3
pre_prob post_prob_if_positive post_prob_if_negative
<dbl> <dbl> <dbl>
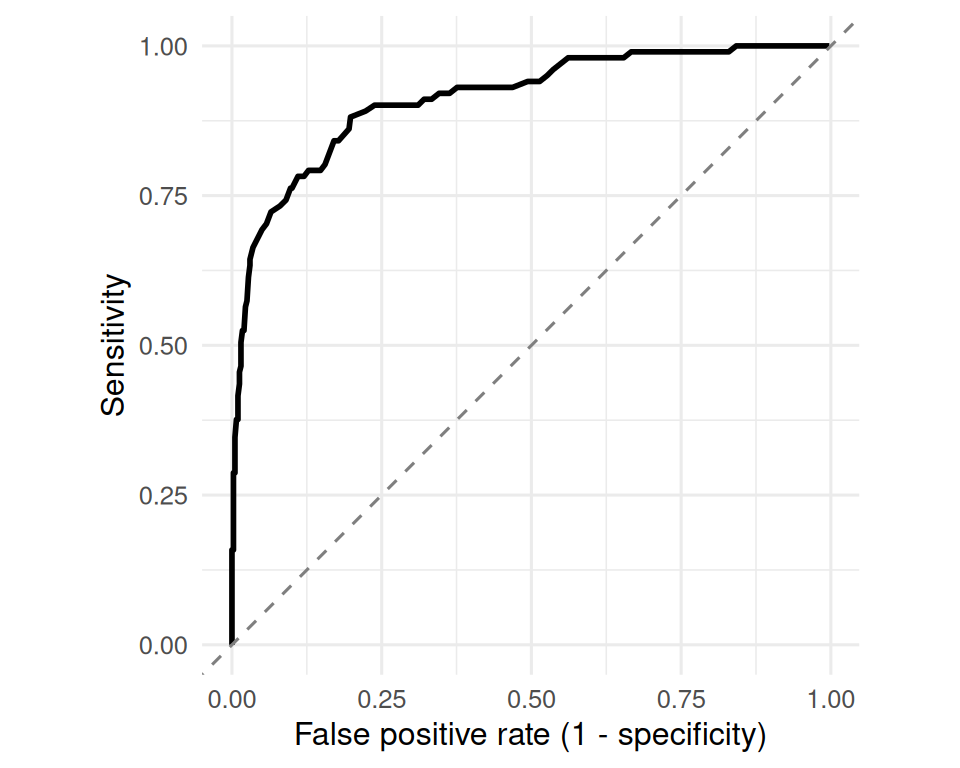
1 0.1 0.399 0.0259Sketch an ROC by sweeping the cutoff.
roc <- tibble(
cut = seq(min(pop$biomarker), max(pop$biomarker), length.out = 200)
) |>
rowwise() |>
mutate(
tp = sum(pop$biomarker > cut & pop$disease == 1),
fn = sum(pop$biomarker <= cut & pop$disease == 1),
fp = sum(pop$biomarker > cut & pop$disease == 0),
tn = sum(pop$biomarker <= cut & pop$disease == 0),
sens = tp / (tp + fn),
fpr = fp / (fp + tn)
) |>
ungroup()