Week 2, Session 5 — Continuous distributions and Q-Q plots
Course 1 — #courses
2. Visualise
Plot densities side by side.
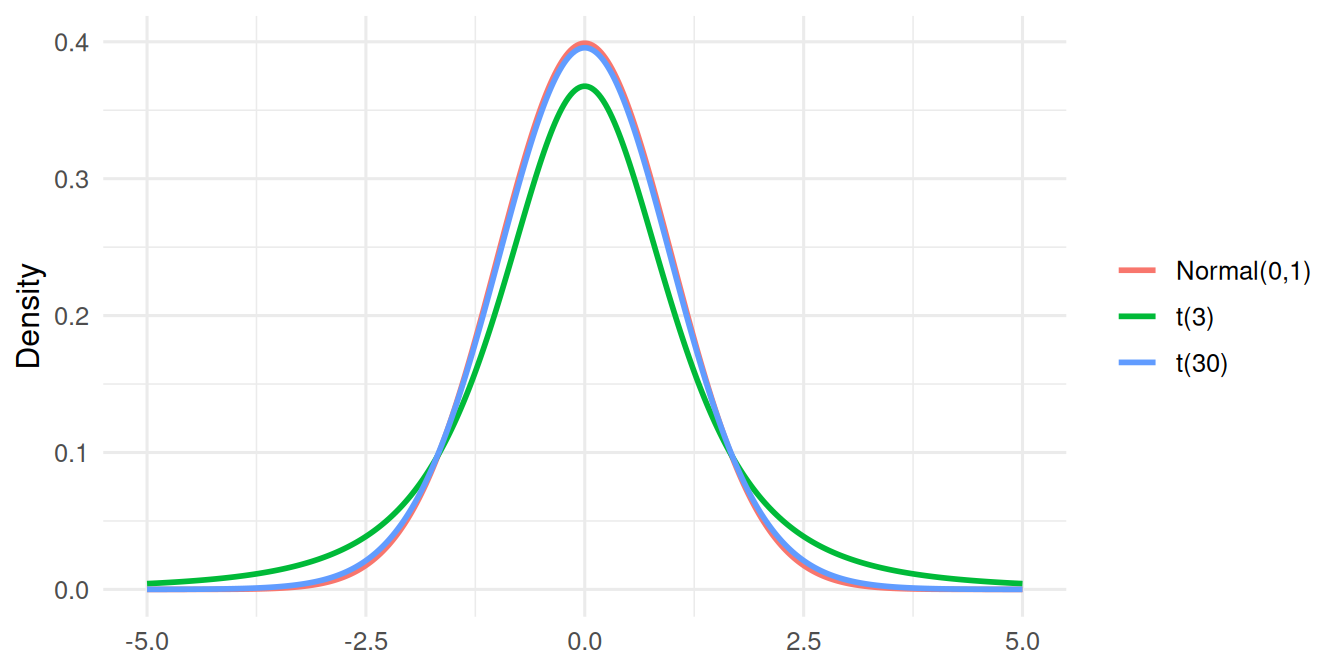
The t with 3 df has visibly heavier tails; at 30 df it is nearly normal.
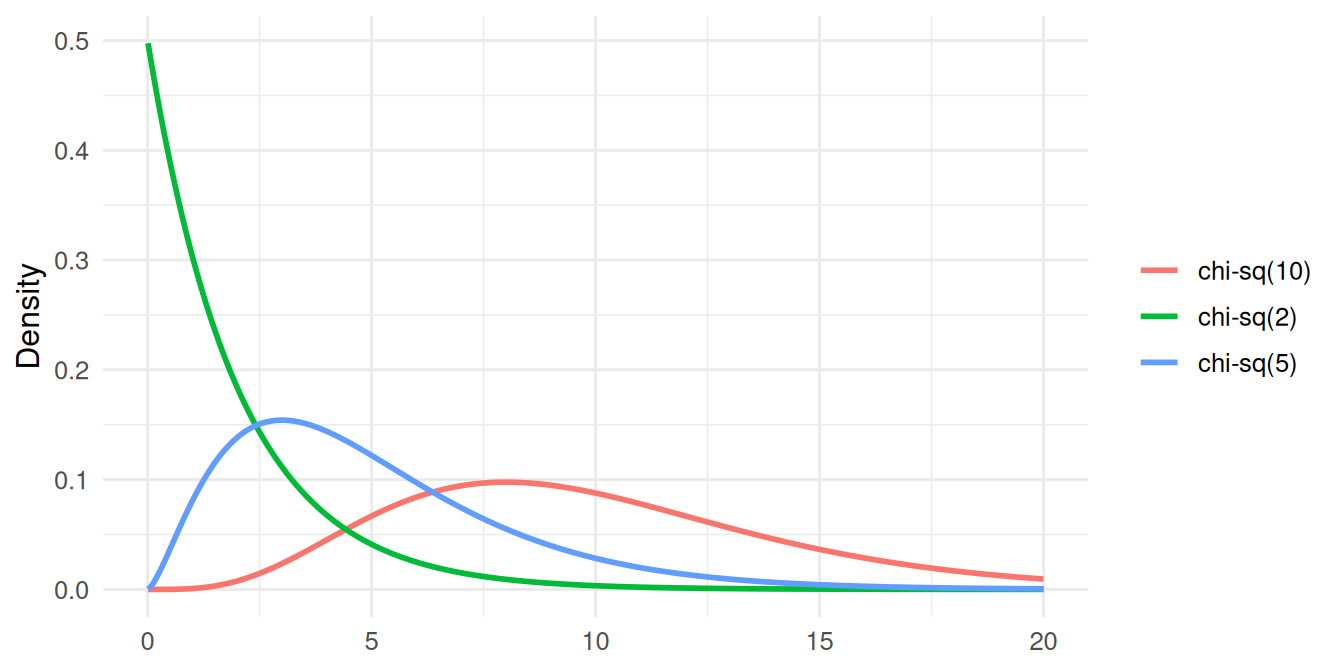
3. Assumptions
We assume samples are independent and identically distributed. For the Q-Q check, the sample must be reasonably sized (say, at least 20 observations) for the plot to be informative.
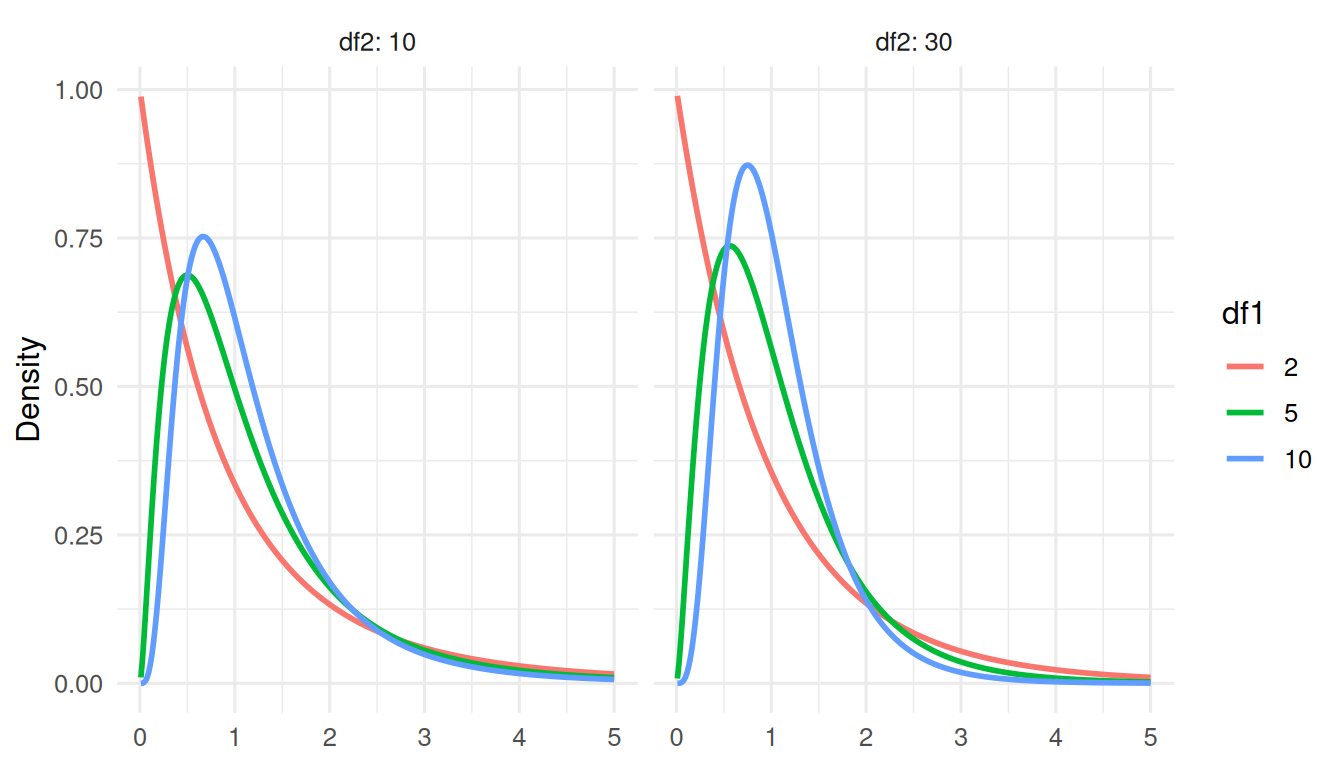
4. Conduct
Q-Q plots. Simulate data, compare to a hypothesised distribution.
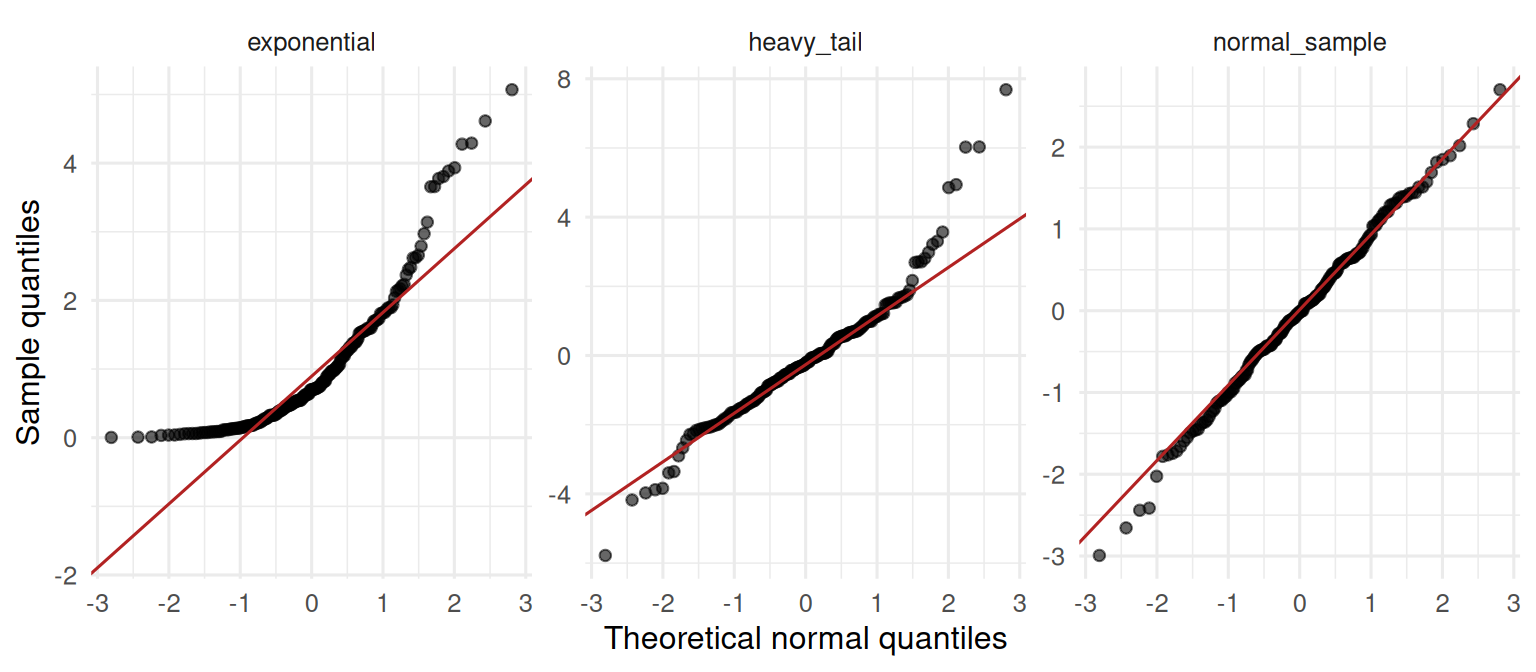
The normal sample lies on the 45° reference line; the heavy-tailed sample splays at both ends; the exponential curves away on one side.
Shapiro-Wilk as a quick numerical check on the three samples.