Week 3, Session 1 — Populations, samples, and the central limit theorem
Course 1 — #courses
2. Visualise
Draw from an exponential population and show the distribution of individual observations.
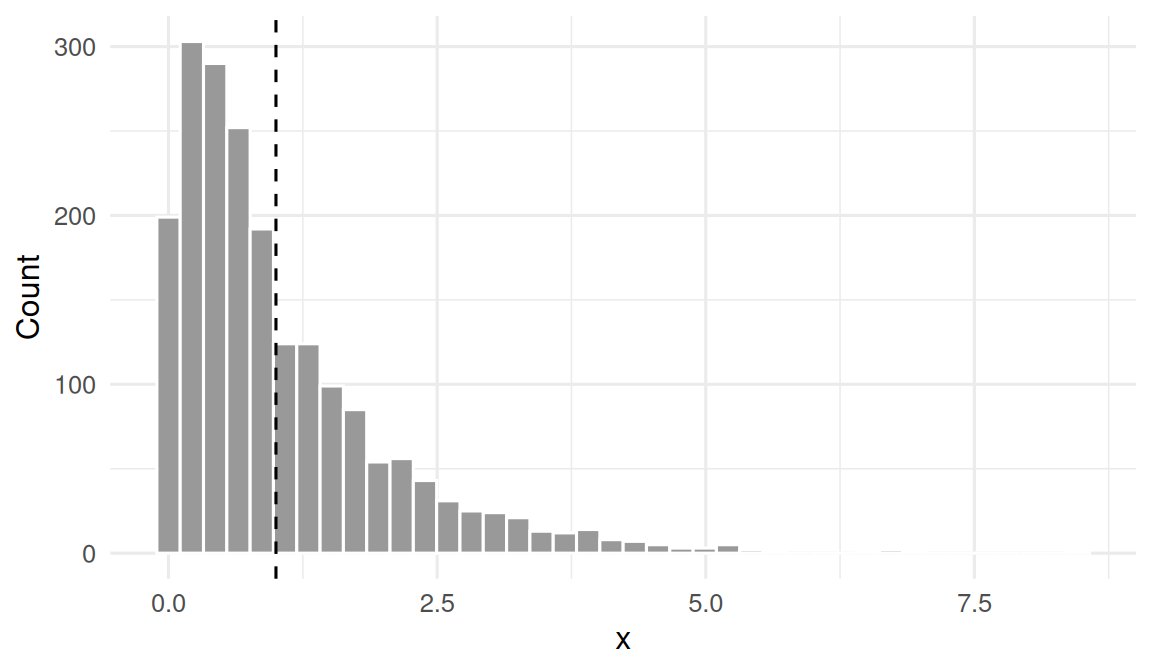
4. Conduct
Plot the sampling distribution of the mean across growing n.
sim_means <- function(n, B = 4000) {
replicate(B, mean(rexp(n, rate = rate)))
}
means_df <- bind_rows(
tibble(n = "n = 2", mean = sim_means(2)),
tibble(n = "n = 5", mean = sim_means(5)),
tibble(n = "n = 30", mean = sim_means(30)),
tibble(n = "n = 100", mean = sim_means(100))
) |>
mutate(n = factor(n, levels = c("n = 2", "n = 5", "n = 30", "n = 100")))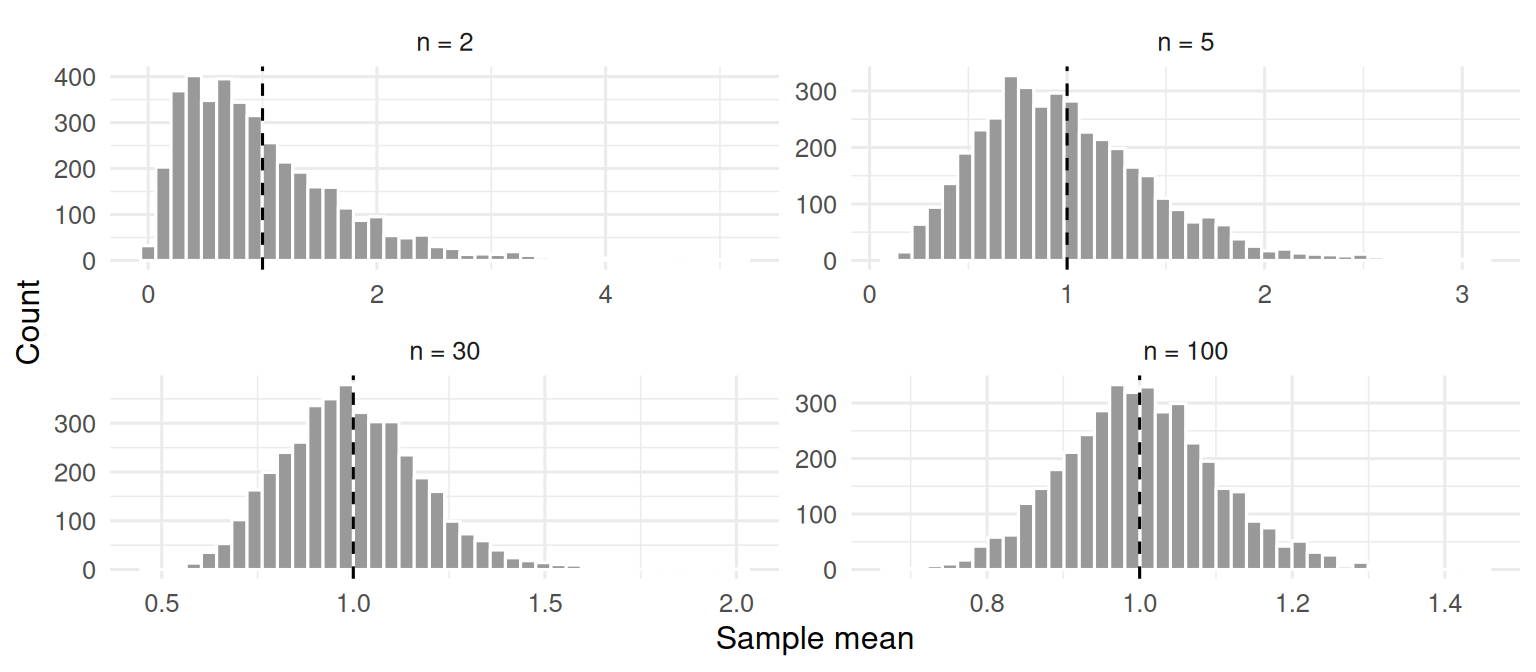
The histograms widen (more spread with small n) and are strongly right-skewed at n = 2. By n = 30 they are close to symmetric.
# A tibble: 5 × 7
n bias variance mse se expected_se ratio
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 5 -0.000703 0.200 0.200 0.447 0.447 0.999
2 10 -0.00189 0.100 0.100 0.317 0.316 1.00
3 30 -0.00528 0.0331 0.0331 0.182 0.183 0.996
4 100 -0.000430 0.0101 0.0101 0.100 0.1 1.00
5 500 0.000726 0.00198 0.00198 0.0445 0.0447 0.996