Week 3, Session 2 — Bootstrap and permutation tests
Course 1 — #courses
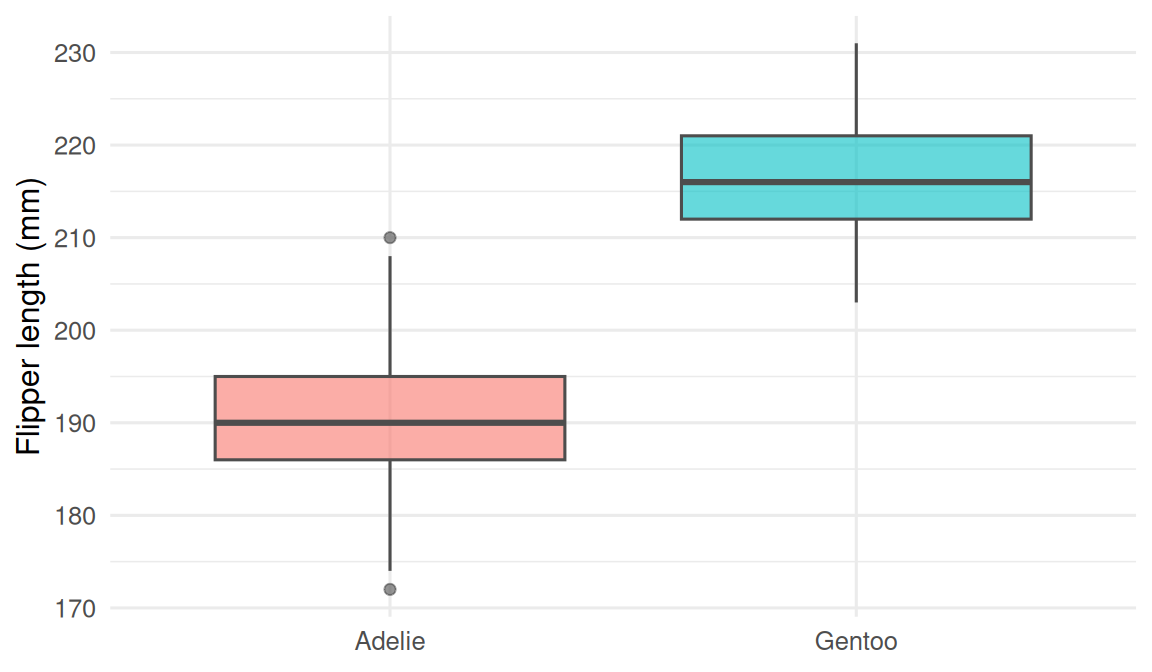
2. Visualise
Use palmerpenguins.
4. Conduct
Bootstrap CI for the median body mass of Gentoo
gen <- dat |> filter(species == "Gentoo") |> pull(body_mass_g)
B <- 2000
boot_meds <- replicate(B, median(sample(gen, replace = TRUE)))
ci_med <- quantile(boot_meds, c(0.025, 0.975))
obs_med <- median(gen)
tibble(statistic = "median body mass",
observed = obs_med,
ci_low = ci_med[1],
ci_high = ci_med[2])# A tibble: 1 × 4
statistic observed ci_low ci_high
<chr> <int> <dbl> <dbl>
1 median body mass 5000 4900 5200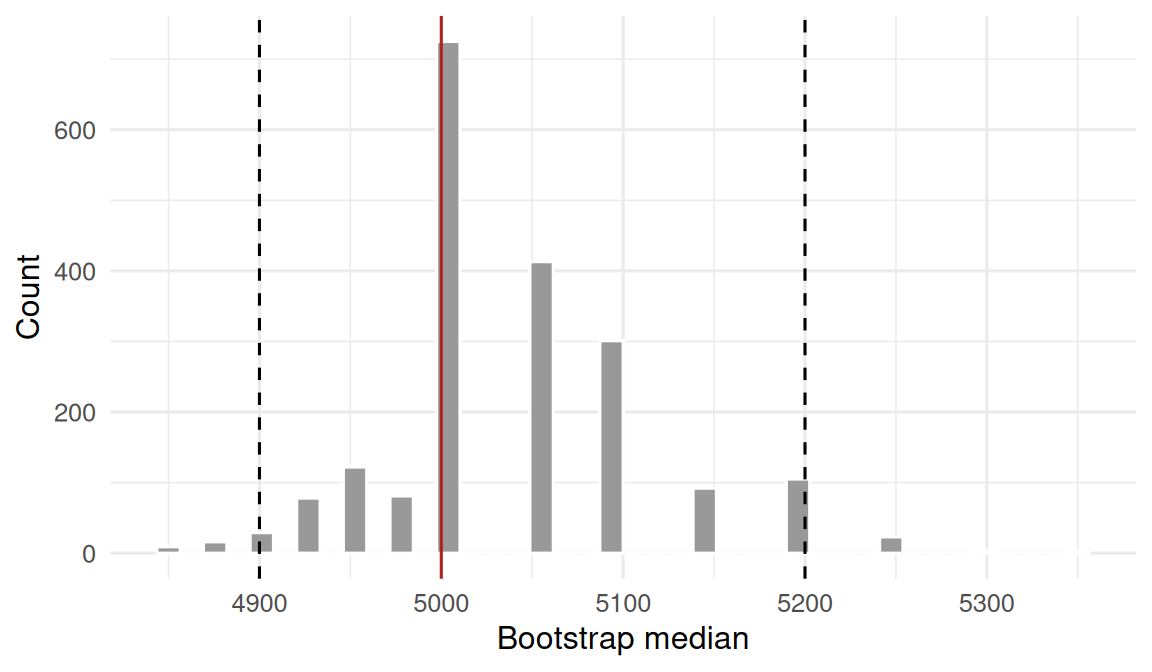
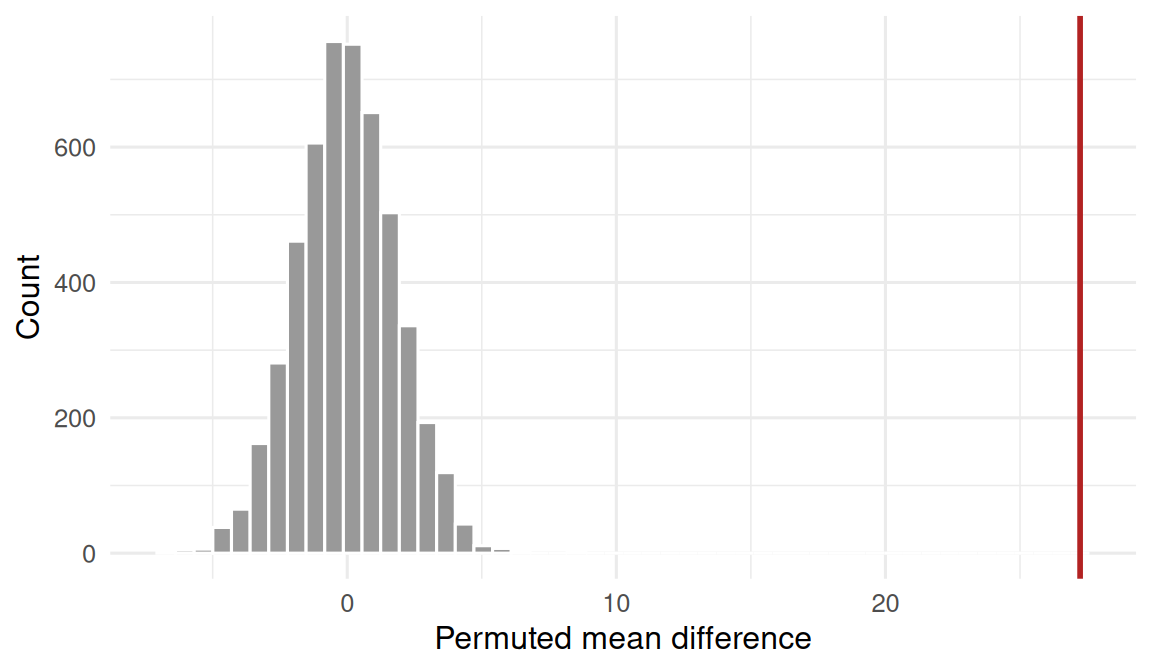
Permutation test for flipper length Gentoo vs Adelie
[1] 0