Week 3, Session 3 — Maximum likelihood estimation
Course 1 — #courses
2. Visualise
Normal data with known σ = 2.
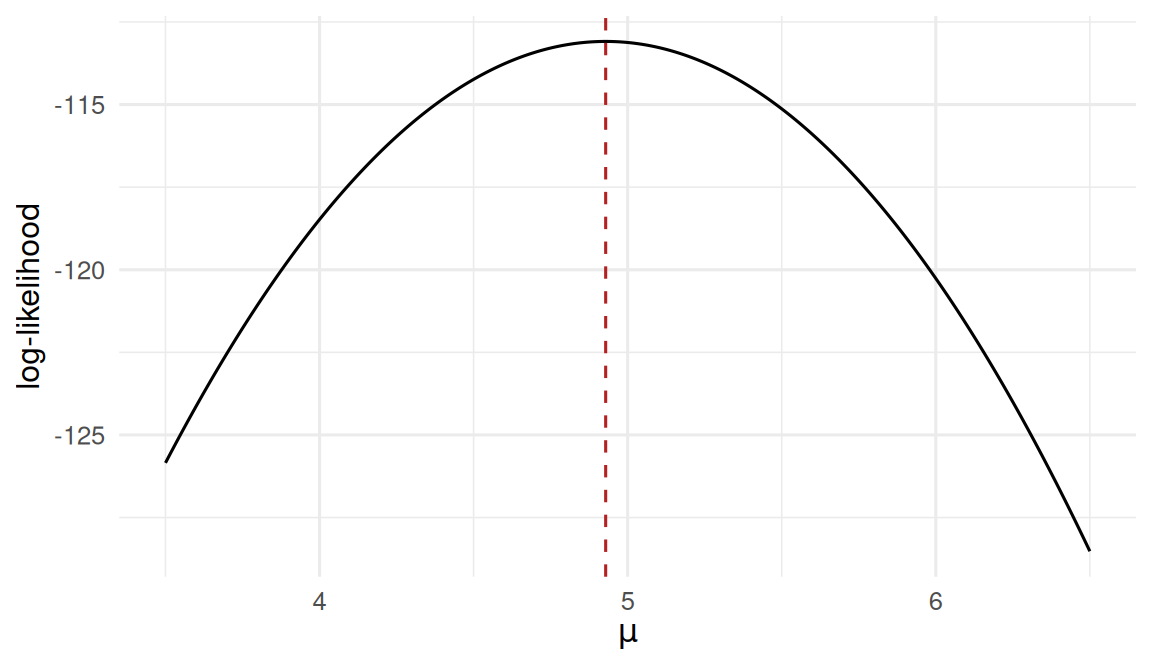
The likelihood is peaked at the sample mean — that is the MLE.
4. Conduct
Normal mean by MLE
# A tibble: 1 × 4
mle se ci_low ci_high
<dbl> <dbl> <dbl> <dbl>
1 4.93 0.283 4.37 5.48Normal mean by numeric optimisation (sanity check)
[1] 4.928656[1] 0.2828427Poisson rate by MLE
y <- rpois(100, lambda = 3.2)
mle_lambda <- mean(y)
# Fisher information for lambda: n / lambda. At MLE use 1/mle_lambda per obs.
I_lambda <- length(y) / mle_lambda
se_lambda <- 1 / sqrt(I_lambda)
ci_lambda <- mle_lambda + c(-1, 1) * qnorm(0.975) * se_lambda
tibble(mle = mle_lambda, se = se_lambda,
ci_low = ci_lambda[1], ci_high = ci_lambda[2])# A tibble: 1 × 4
mle se ci_low ci_high
<dbl> <dbl> <dbl> <dbl>
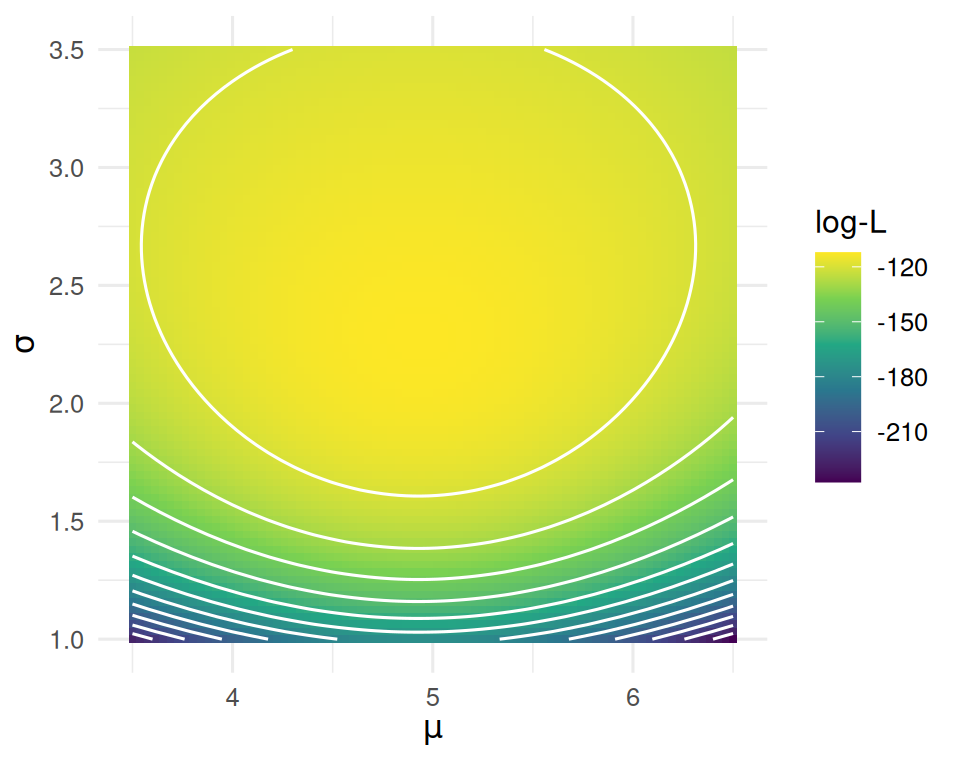
1 3.24 0.18 2.89 3.59Likelihood surface for a two-parameter model (μ, σ)