Week 3, Session 5 — Hypothesis testing, p-values, type I/II errors
Course 1 — #courses
2. Visualise
Generate many datasets with no effect, run a t-test on each, and plot the distribution of p-values.
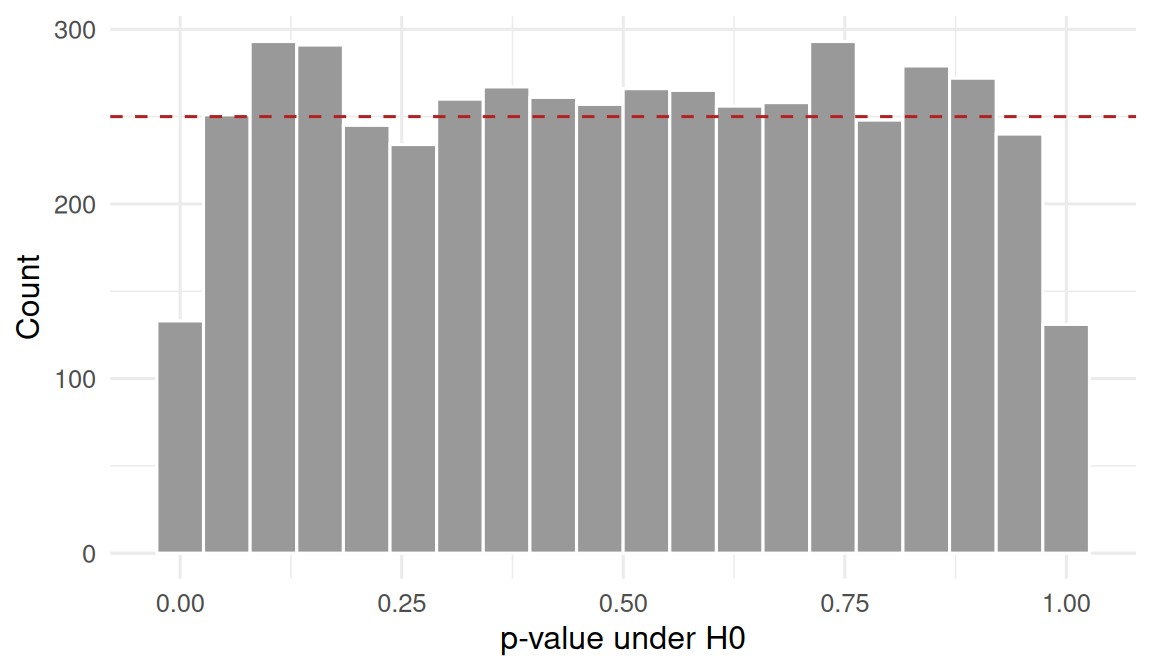
Flat histogram. Any other shape is a sign the test is misspecified.
4. Conduct
Type I error rate
Close to the nominal 0.05.
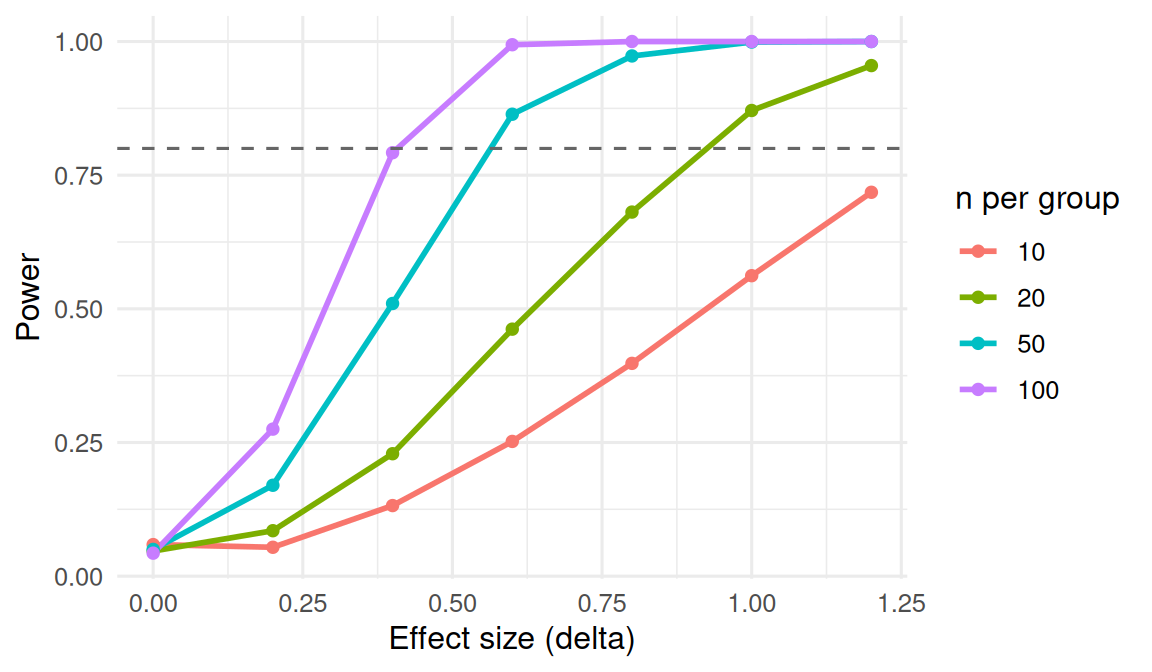
Power under H1 (effect size 0.5, n per group 30)
Power by effect size and sample size