Week 4, Session 1 — Two-sample and paired t-tests
Course 1 — #courses
2. Visualise
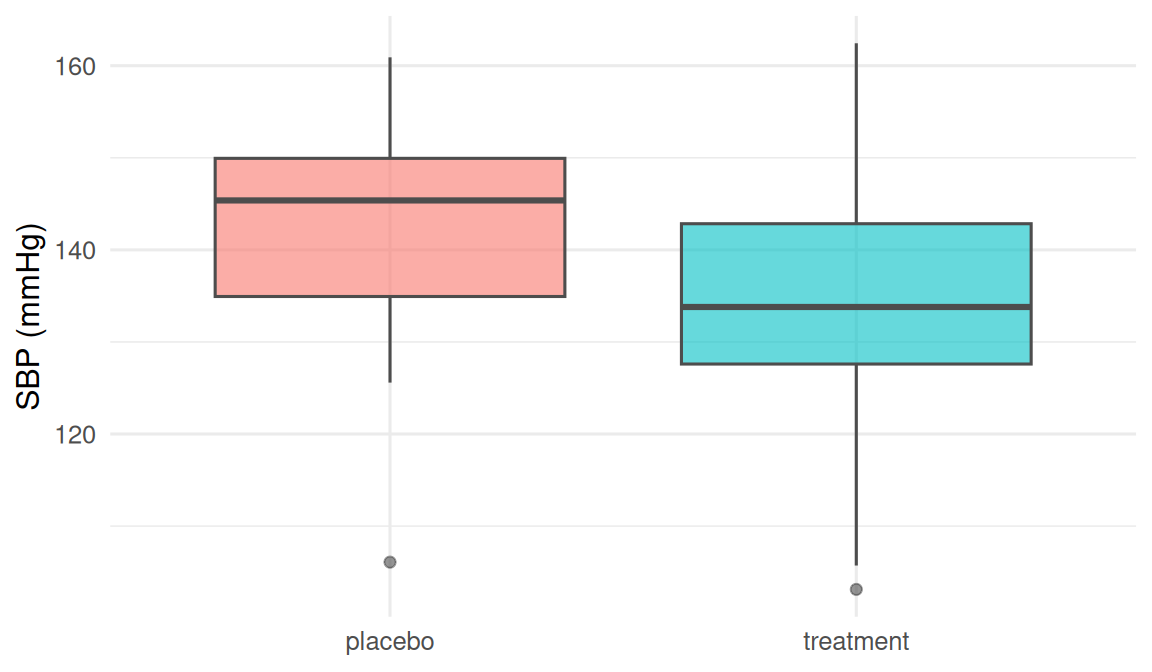
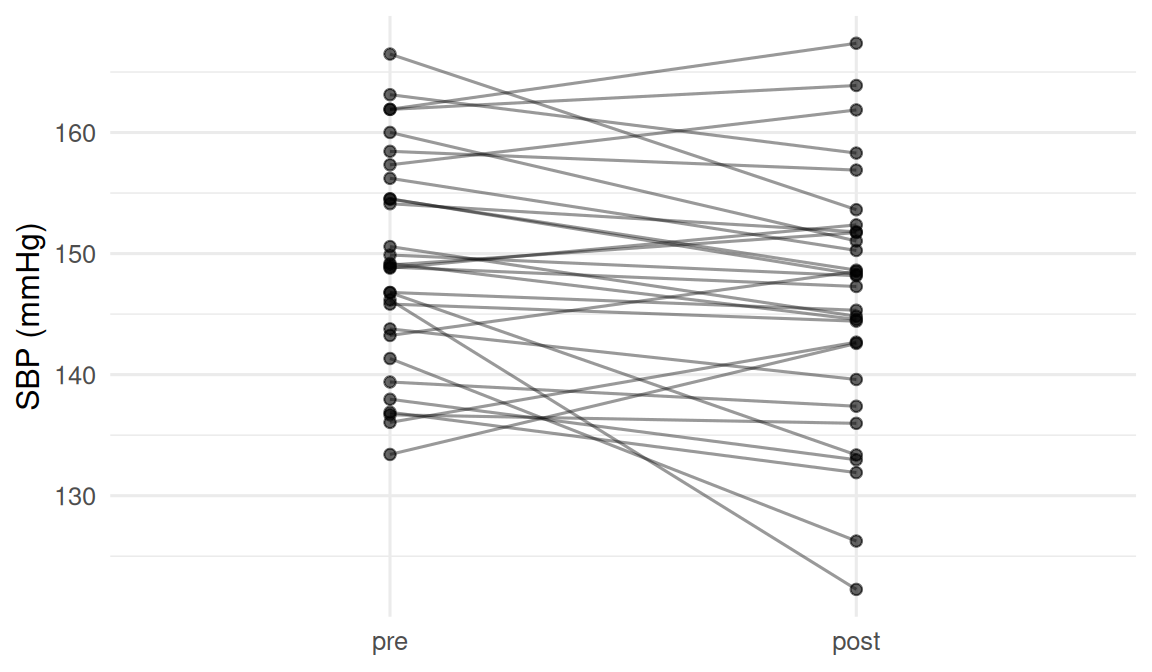
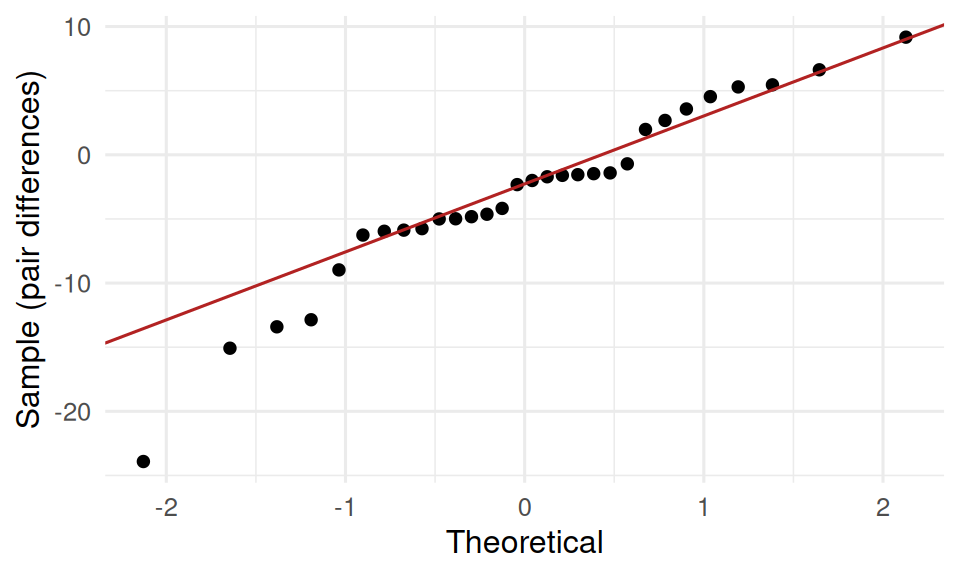
3. Assumptions
Independent t: approximate normality of the sample means; Welch’s does not require equal variances. Paired t: approximate normality of the within-subject differences.