Week 4, Session 3 — Pearson and Spearman correlation
Course 1 — #courses
2. Visualise
4. Conduct
p1_pearson <- cor.test(x, y_linear, method = "pearson")
p1_spearman <- cor.test(x, y_linear, method = "spearman", exact = FALSE)
p2_pearson <- cor.test(x, y_monotone, method = "pearson")
p2_spearman <- cor.test(x, y_monotone, method = "spearman", exact = FALSE)
tibble(
relationship = c("linear", "linear", "monotone", "monotone"),
method = c("Pearson", "Spearman", "Pearson", "Spearman"),
r_or_rho = c(p1_pearson$estimate, p1_spearman$estimate,
p2_pearson$estimate, p2_spearman$estimate),
p = c(p1_pearson$p.value, p1_spearman$p.value,
p2_pearson$p.value, p2_spearman$p.value)
)# A tibble: 4 × 4
relationship method r_or_rho p
<chr> <chr> <dbl> <dbl>
1 linear Pearson 0.570 1.27e-18
2 linear Spearman 0.528 8.89e-16
3 monotone Pearson 0.762 2.90e-39
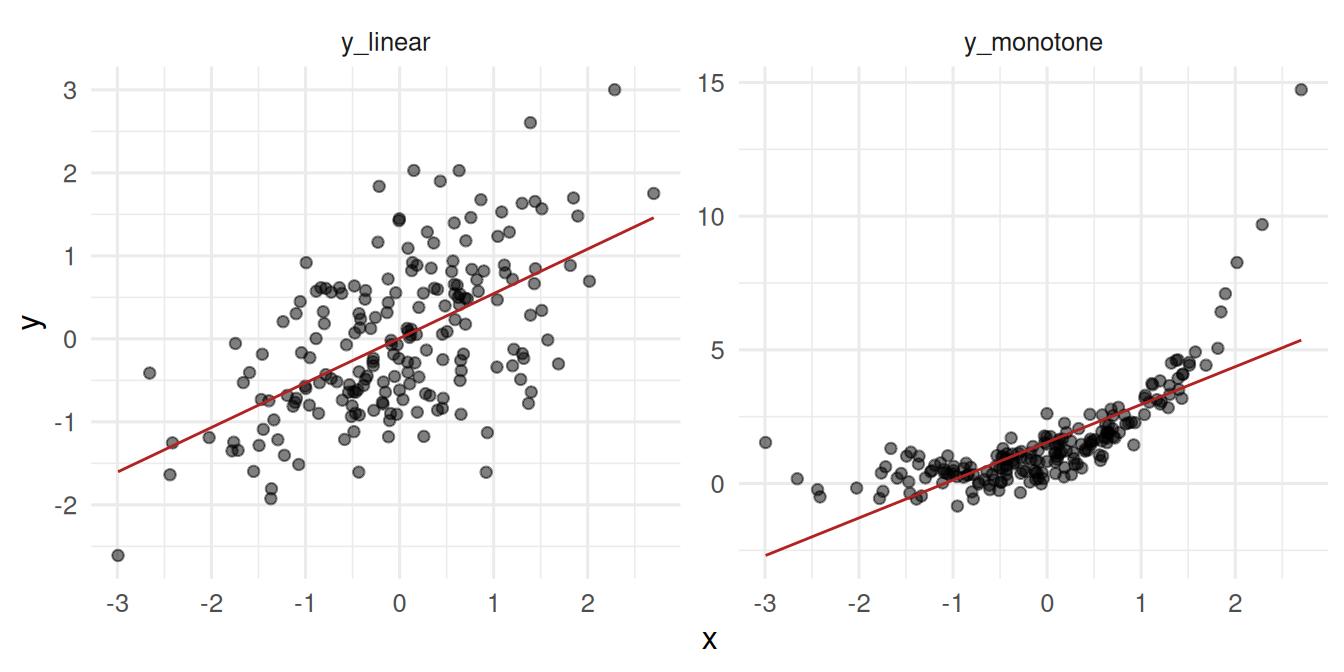
4 monotone Spearman 0.833 7.32e-53The monotonic non-linear relationship gives a much higher Spearman than Pearson — the rank correlation sees the perfect monotonicity.
The DatasauRus demonstration
# A tibble: 6 × 6
dataset mean_x mean_y sd_x sd_y r
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 away 54.3 47.8 16.8 26.9 -0.0641
2 bullseye 54.3 47.8 16.8 26.9 -0.0686
3 circle 54.3 47.8 16.8 26.9 -0.0683
4 dino 54.3 47.8 16.8 26.9 -0.0645
5 dots 54.3 47.8 16.8 26.9 -0.0603
6 h_lines 54.3 47.8 16.8 26.9 -0.0617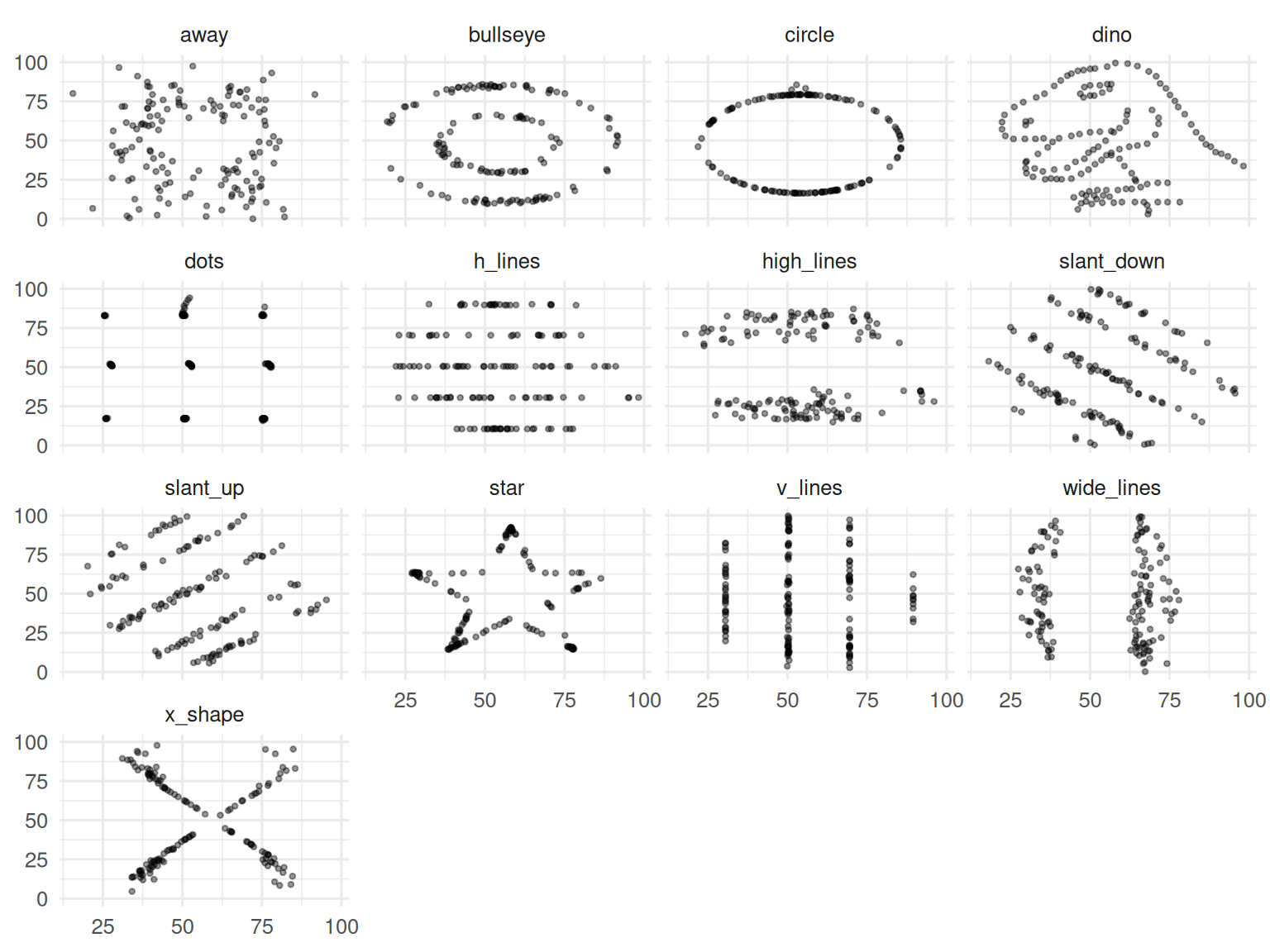
Thirteen datasets; all have mean x ≈ 54, mean y ≈ 47, SDs ≈ 17 and 26, and Pearson r ≈ −0.06. The shapes are wildly different.