Week 1, Session 4 — Diagnostics: residuals, QQ, leverage, Cook’s distance, VIF
Course 2 — #courses
2. Visualise
n <- 150
x1 <- rnorm(n, 0, 1)
x2 <- x1 + rnorm(n, 0, 0.3) # x1 and x2 correlated
x3 <- rnorm(n, 0, 1)
y <- 1 + 2 * x1 - 1.5 * x2 + 0.5 * x3 + rnorm(n, 0, 1 + 0.4 * abs(x1))
# add one influential point
x1[1] <- 5; x2[1] <- 5; y[1] <- 0
dat <- tibble(y, x1, x2, x3)
ggplot(dat, aes(x1, y)) +
geom_point(alpha = 0.6) +
labs(x = "x1", y = "y")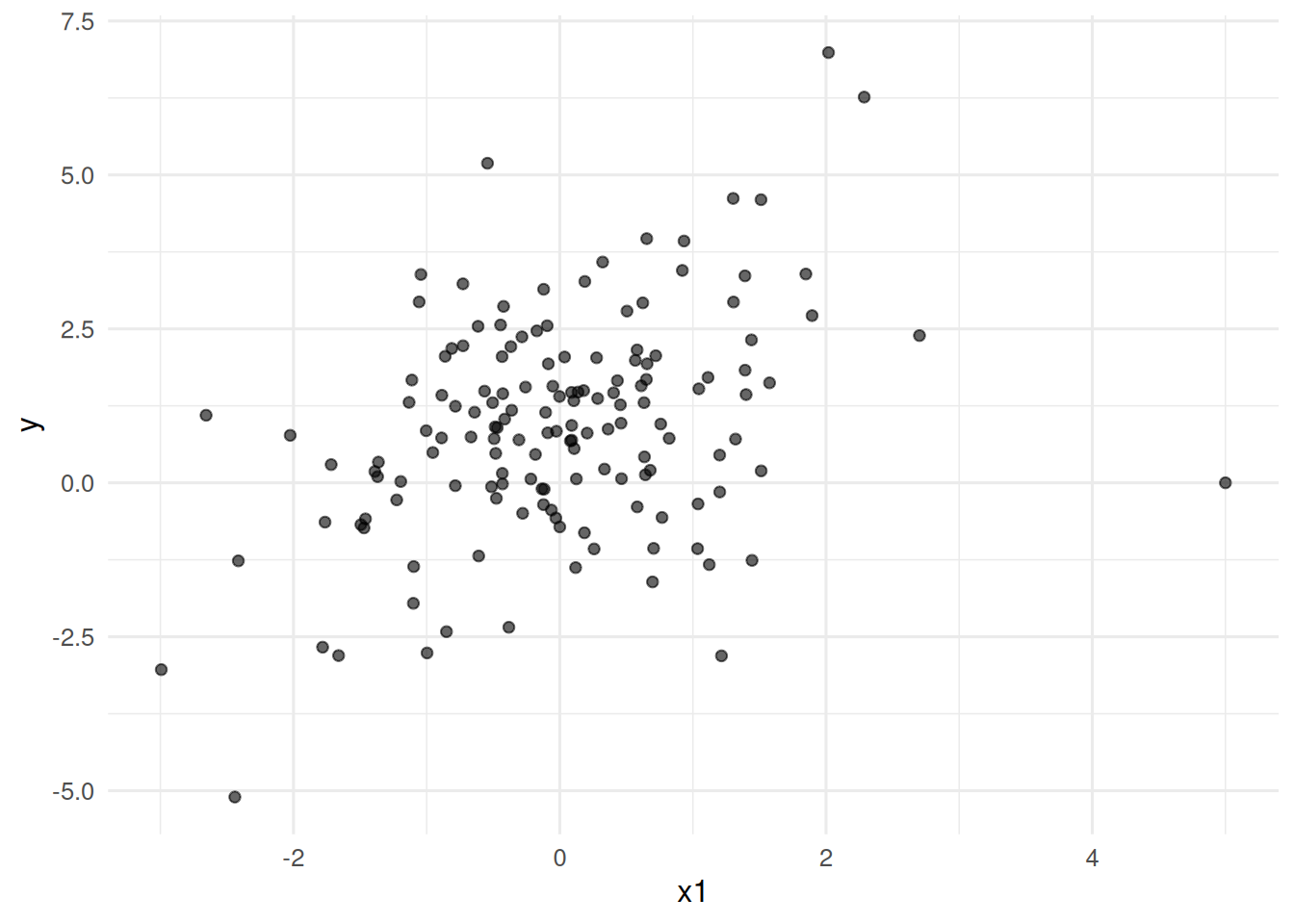
3. Assumptions
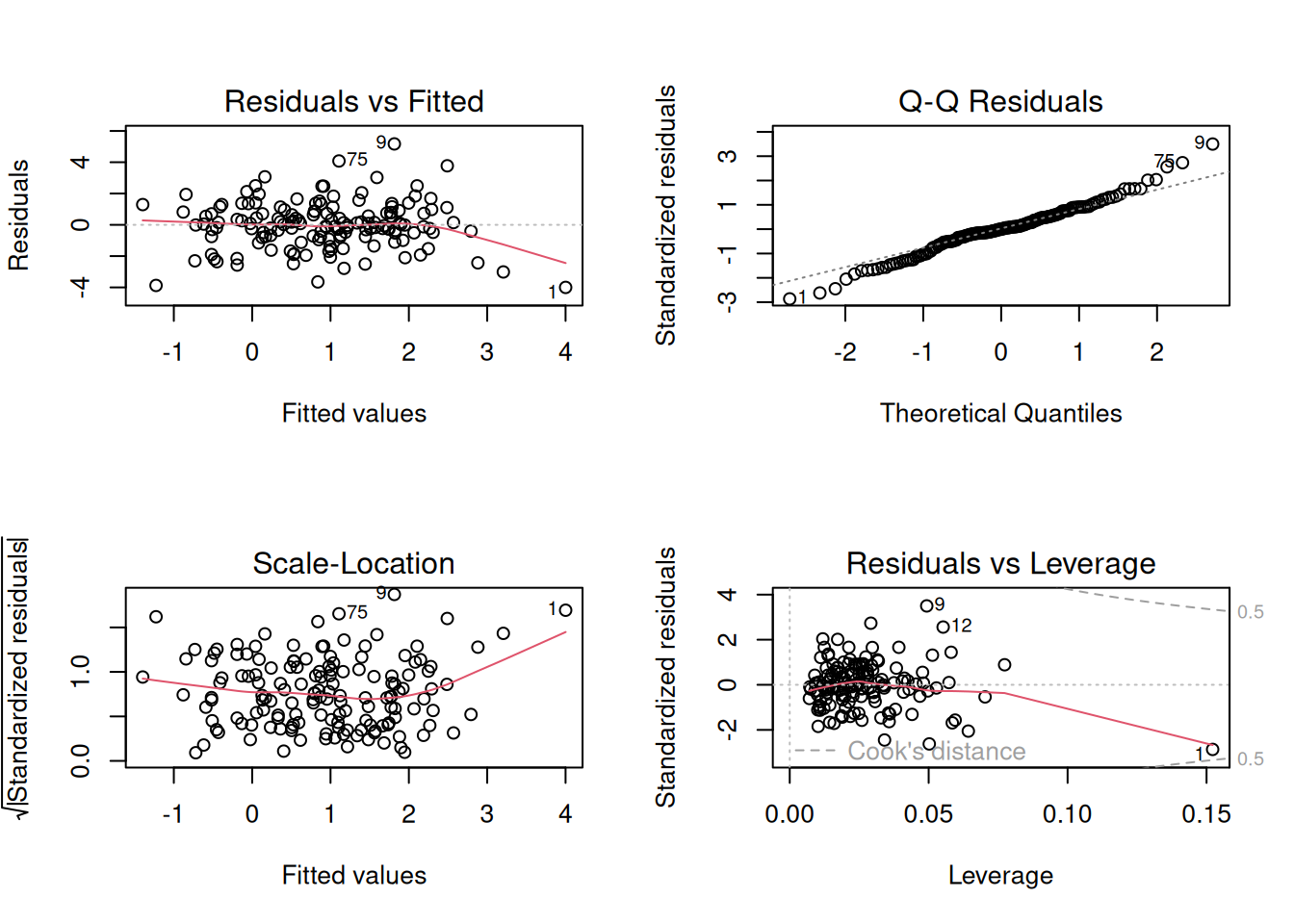
The residuals-vs-fitted plot should show no trend. The QQ plot should track the line. Scale-location should be flat. Residuals-vs-leverage should have no points outside the Cook’s-distance contours.
4. Conduct
Influence diagnostics:
# A tibble: 5 × 5
row .fitted .resid .hat .cooksd
<int> <dbl> <dbl> <dbl> <dbl>
1 1 4.00 -4.00 0.152 0.369
2 9 1.81 5.17 0.0493 0.159
3 12 2.49 3.77 0.0552 0.0958
4 19 -1.23 -3.88 0.0502 0.0909
5 81 3.21 -3.01 0.0643 0.0724VIF:
Performance summary:
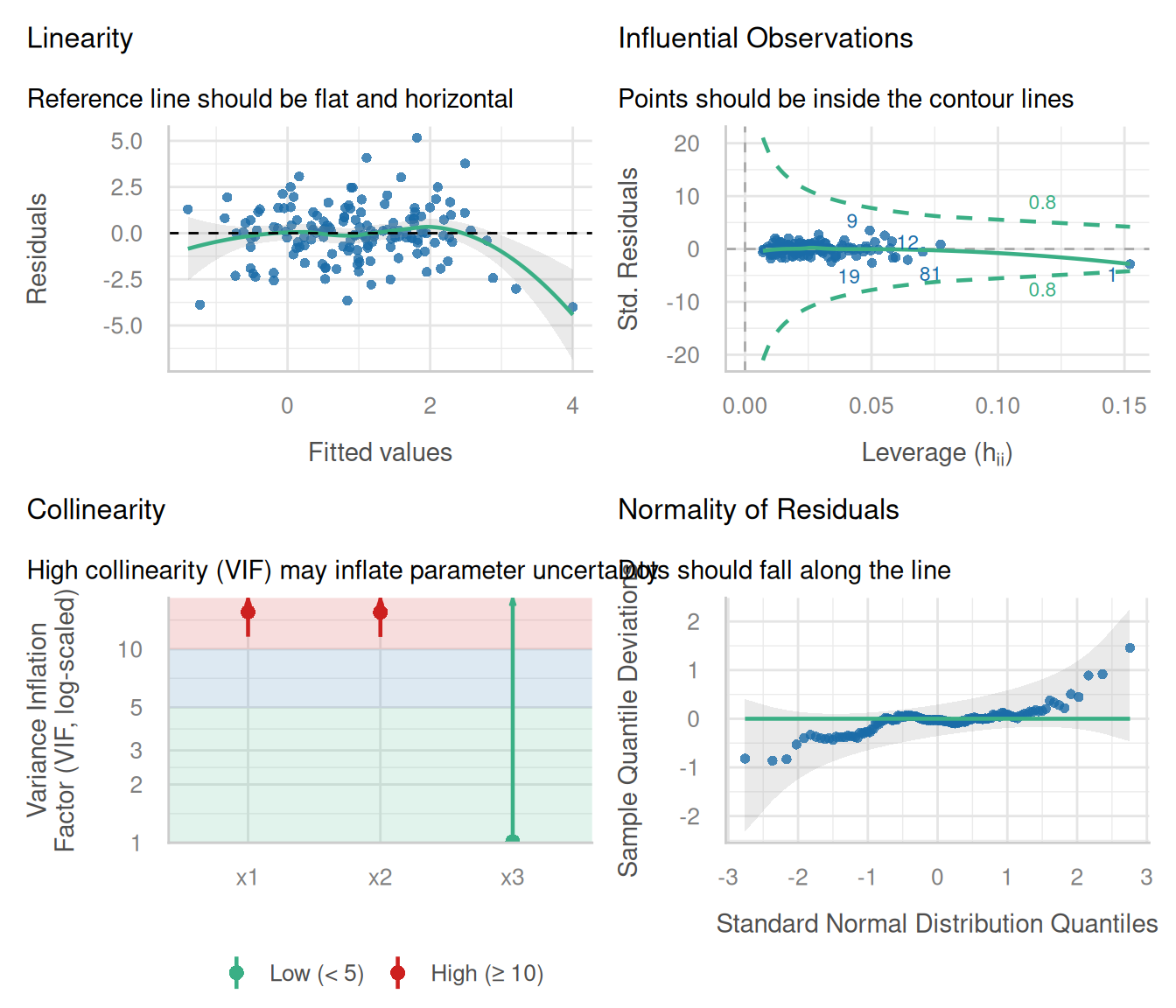
VIF for x1 and x2 should be high; x3 should be fine. The first row (the injected leverage point) should dominate Cook’s distance.