Week 2, Session 3 — RCBD and repeated measures → mixed models
Course 2 — #courses
2. Visualise
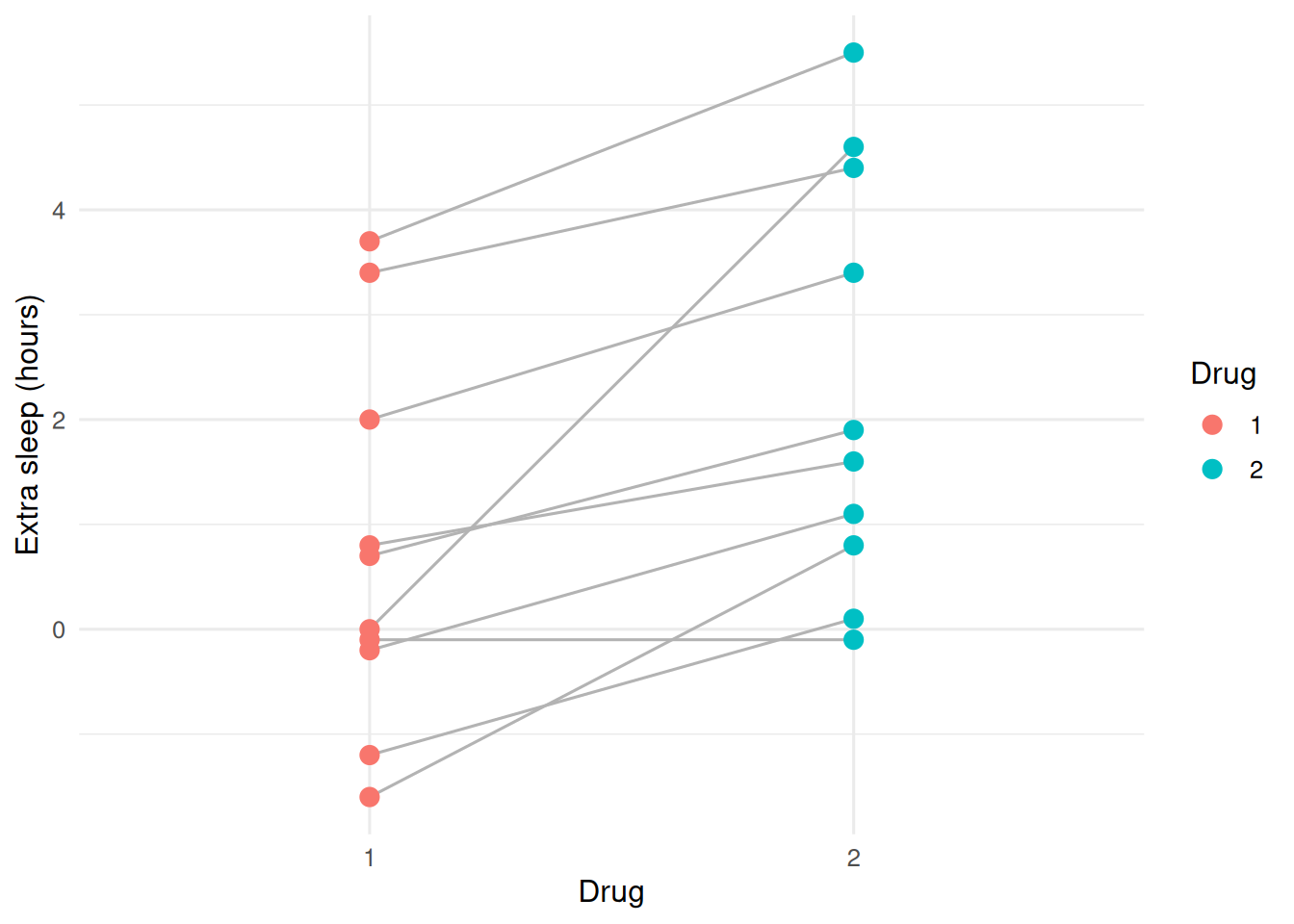
Lines track each subject across the two drugs. Most rise from left to right, suggesting drug 2 adds more sleep than drug 1.
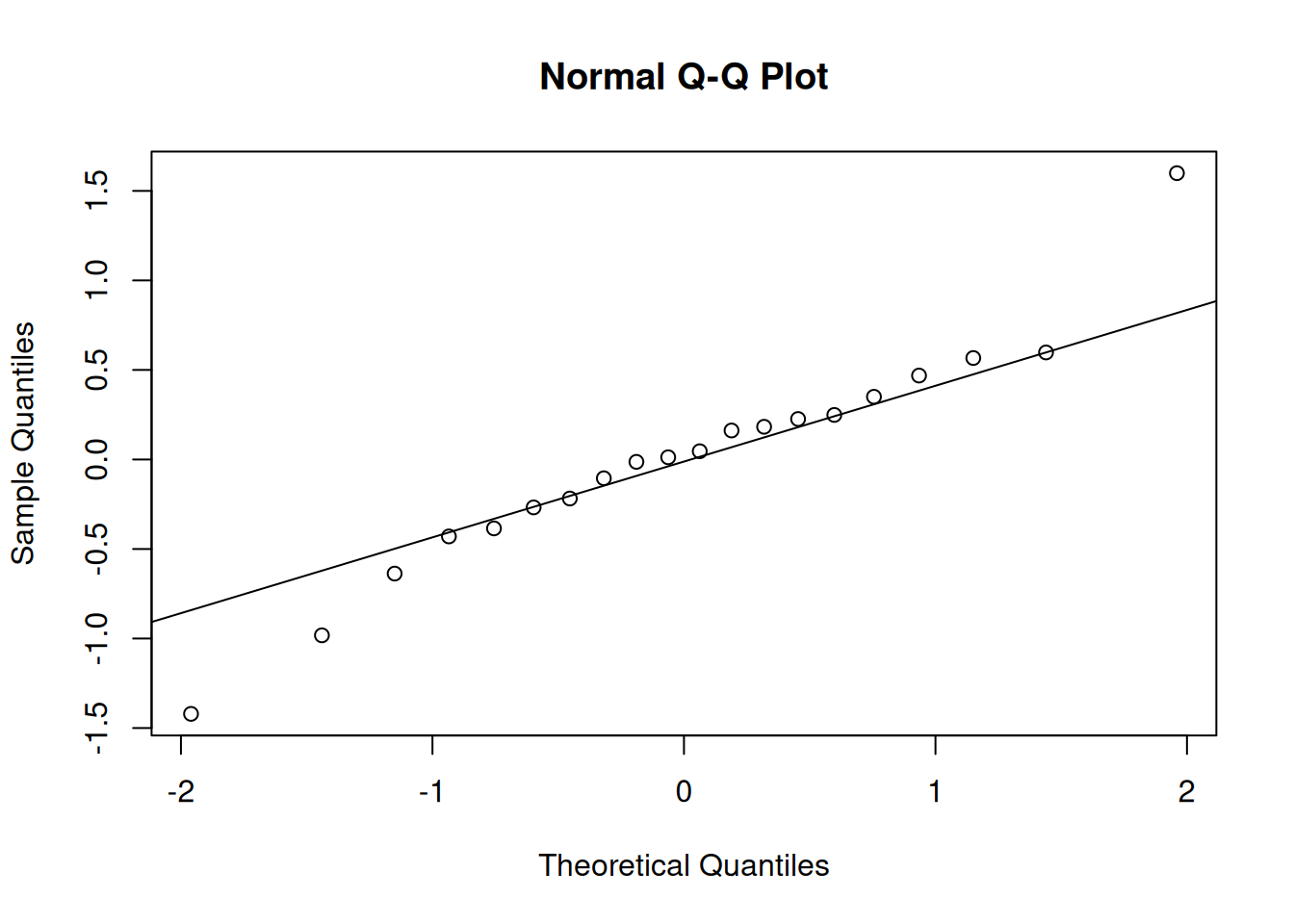
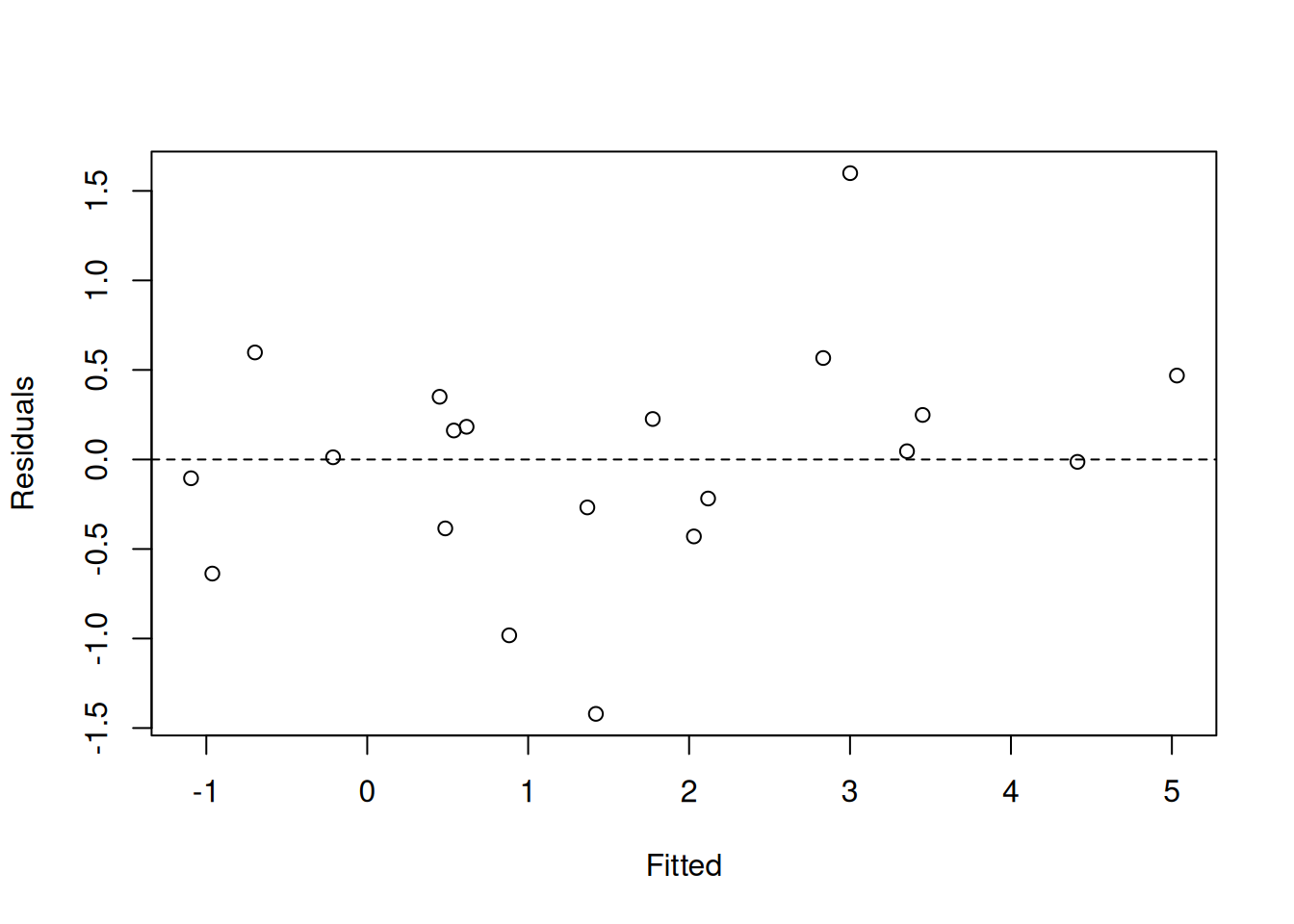
3. Assumptions
Error: ID
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 9 58.08 6.453
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
group 1 12.482 12.482 16.5 0.00283 **
Residuals 9 6.808 0.756
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Residual diagnostics for the mixed version: