Week 4, Session 1 — Dichotomisation, change scores, regression to the mean
Course 2 — #courses
2. Visualise
4. Conduct
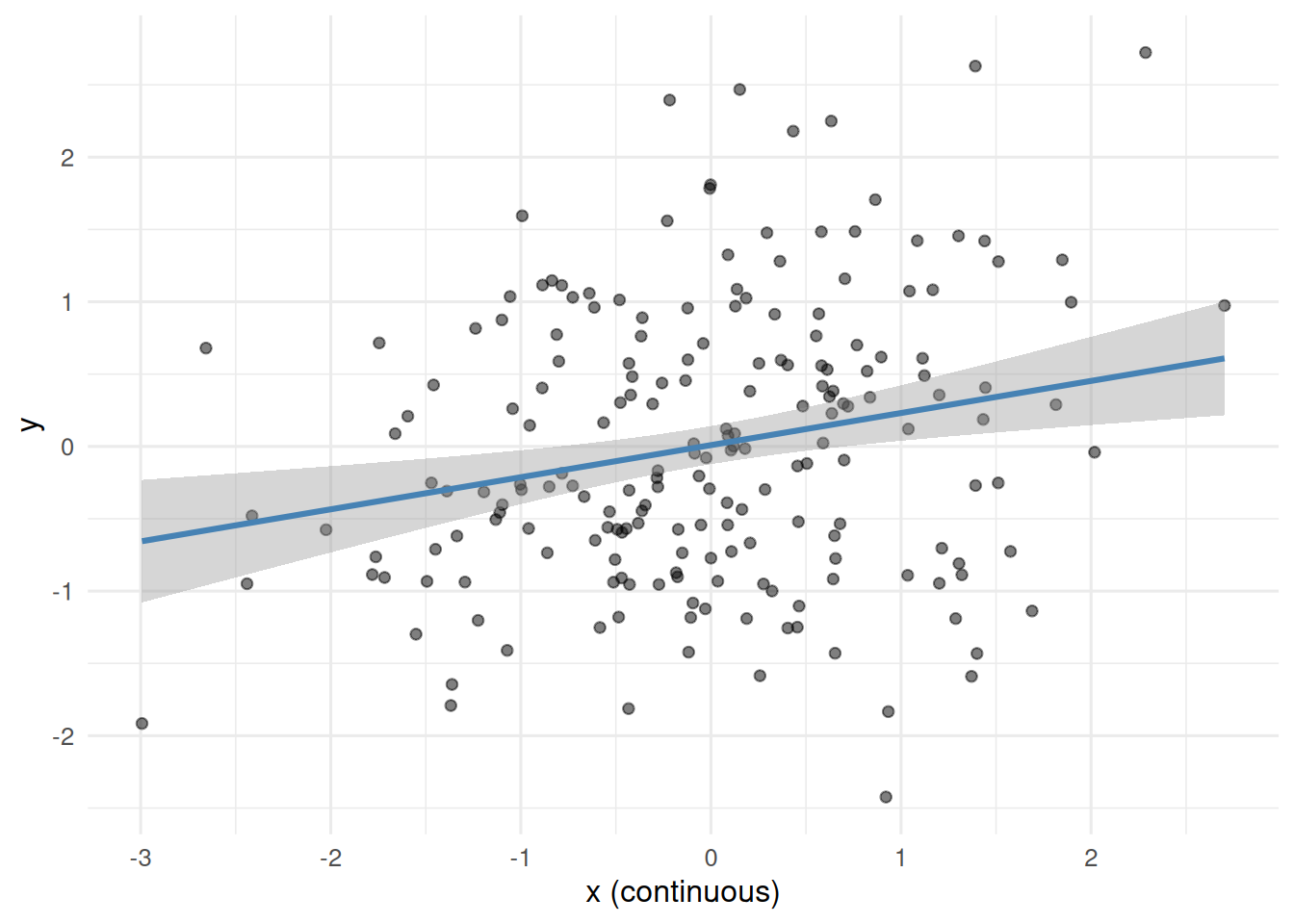
Power loss from dichotomisation:
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 0.00914 0.0669 0.136 0.892
2 x 0.222 0.0688 3.22 0.00148# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 0.191 0.0952 2.01 0.0463
2 x_binlow -0.376 0.135 -2.79 0.00577The p-value for x_bin should be larger than for x; the standard error is larger and the estimate is attenuated.
Regression to the mean:
# A tibble: 2 × 4
high_baseline pre_mean post_mean change
<lgl> <dbl> <dbl> <dbl>
1 FALSE 94.2 96.2 2.00
2 TRUE 120. 114. -6.30The “high baseline” group shows a large negative mean change; the rest of the sample shows a small positive change. No intervention occurred.
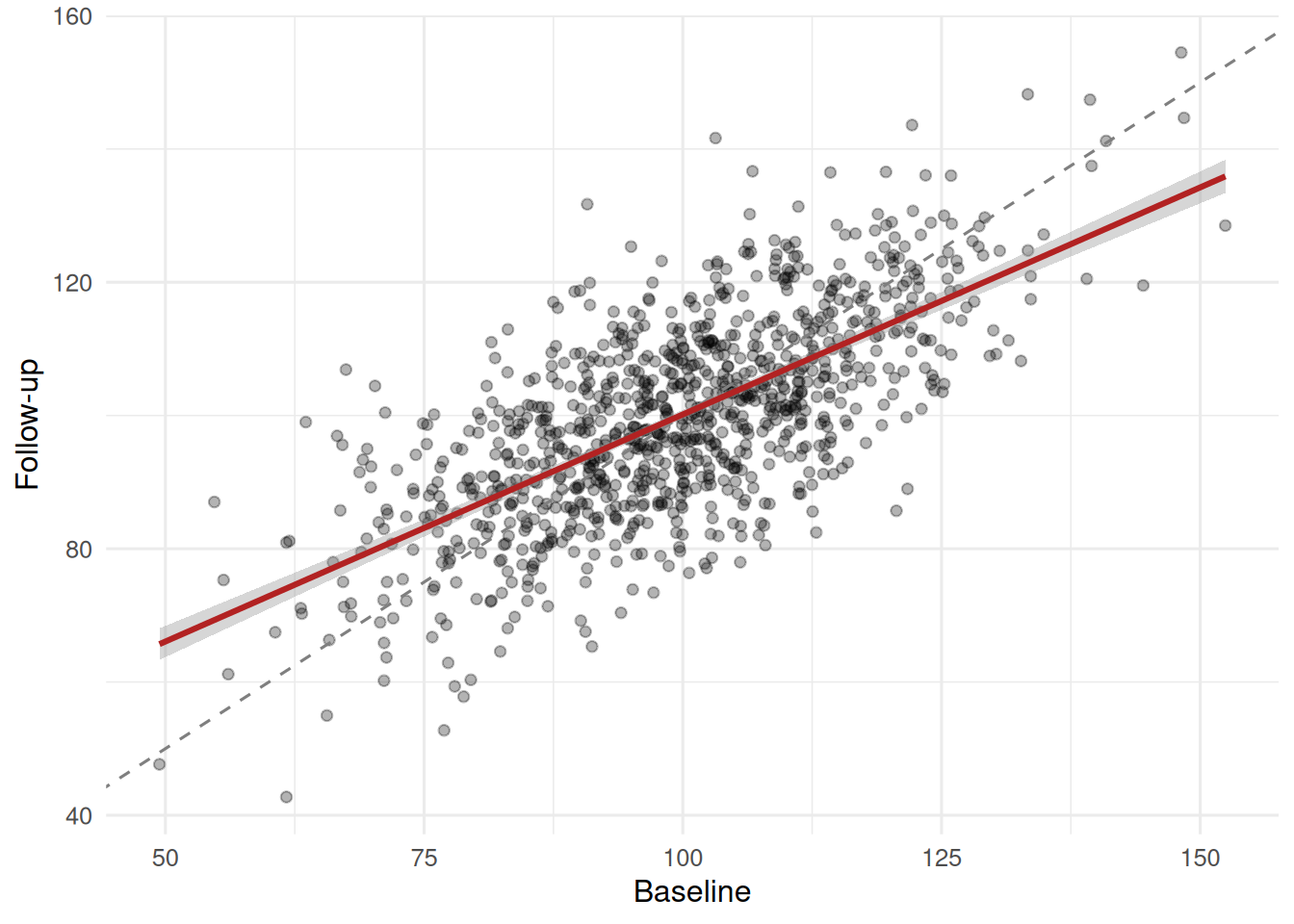
The fitted line is flatter than the identity line; that flattening is RTM.