Week 4, Session 2 — Kappa, ICC, Bland–Altman
Course 2 — #courses
3. Execution
Cohen’s kappa:
Cohen's Kappa for 2 Raters (Weights: unweighted)
Subjects = 100
Raters = 2
Kappa = 0.584
z = 8.21
p-value = 2.22e-16 ICC via psych:
Call: ICC(x = as.matrix(meas))
Intraclass correlation coefficients
type ICC F df1 df2 p lower bound upper bound
Single_raters_absolute ICC1 0.95 43 59 60 1.4e-33 0.93 0.97
Single_random_raters ICC2 0.95 44 59 59 2.1e-33 0.93 0.97
Single_fixed_raters ICC3 0.96 44 59 59 2.1e-33 0.93 0.97
Average_raters_absolute ICC1k 0.98 43 59 60 1.4e-33 0.96 0.99
Average_random_raters ICC2k 0.98 44 59 59 2.1e-33 0.96 0.99
Average_fixed_raters ICC3k 0.98 44 59 59 2.1e-33 0.96 0.99
Number of subjects = 60 Number of Judges = 2
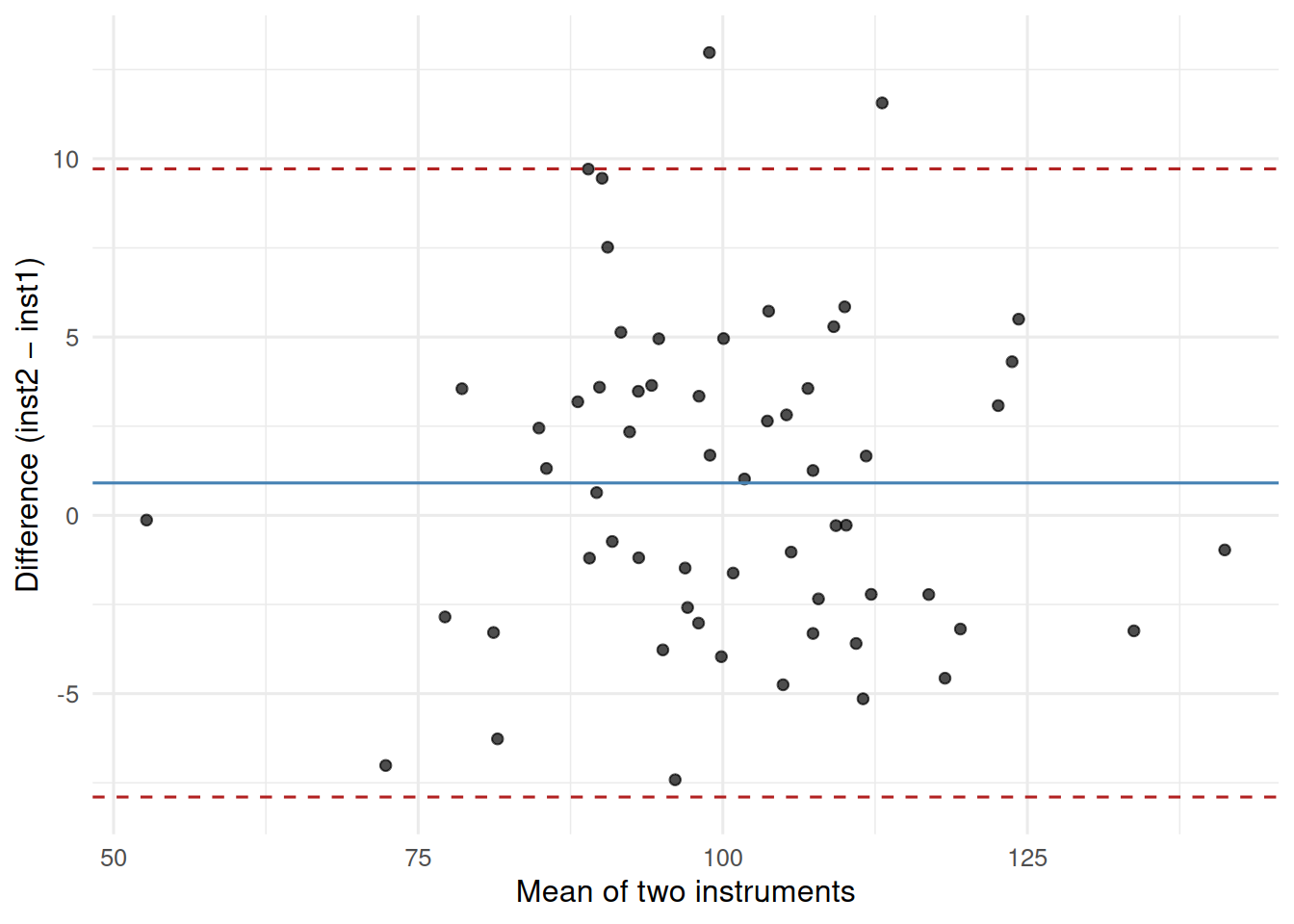
See the help file for a discussion of the other 4 McGraw and Wong estimates,Bland–Altman:
ba <- meas |>
mutate(mean_val = (inst1 + inst2) / 2,
diff_val = inst2 - inst1)
loa <- mean(ba$diff_val) + c(-1.96, 0, 1.96) * sd(ba$diff_val)
ggplot(ba, aes(mean_val, diff_val)) +
geom_point(alpha = 0.7) +
geom_hline(yintercept = loa[1], linetype = 2, colour = "firebrick") +
geom_hline(yintercept = loa[2], linetype = 1, colour = "steelblue") +
geom_hline(yintercept = loa[3], linetype = 2, colour = "firebrick") +
labs(x = "Mean of two instruments",
y = "Difference (inst2 − inst1)")