Week 2, Session 1 — MCAR, MAR, MNAR
Course 3 — #courses
2. Visualise
n <- 1000
df <- tibble(
x = rnorm(n, 50, 10),
y = 2 + 0.5 * x + rnorm(n, 0, 5)
)
mcar <- df |> mutate(y_obs = if_else(runif(n) < 0.30, NA_real_, y),
mech = "MCAR")
mar <- df |> mutate(p = plogis(-2 + 0.05 * (x - 50)),
y_obs = if_else(runif(n) < p, NA_real_, y),
mech = "MAR")
mnar <- df |> mutate(p = plogis(-2 + 0.05 * (y - mean(y))),
y_obs = if_else(runif(n) < p, NA_real_, y),
mech = "MNAR")
all <- bind_rows(
mcar |> select(mech, x, y, y_obs),
mar |> select(mech, x, y, y_obs),
mnar |> select(mech, x, y, y_obs)
)
all |>
mutate(missing = is.na(y_obs)) |>
ggplot(aes(x, y, colour = missing)) +
geom_point(alpha = 0.5) +
facet_wrap(~ mech) +
labs(colour = "Y missing?")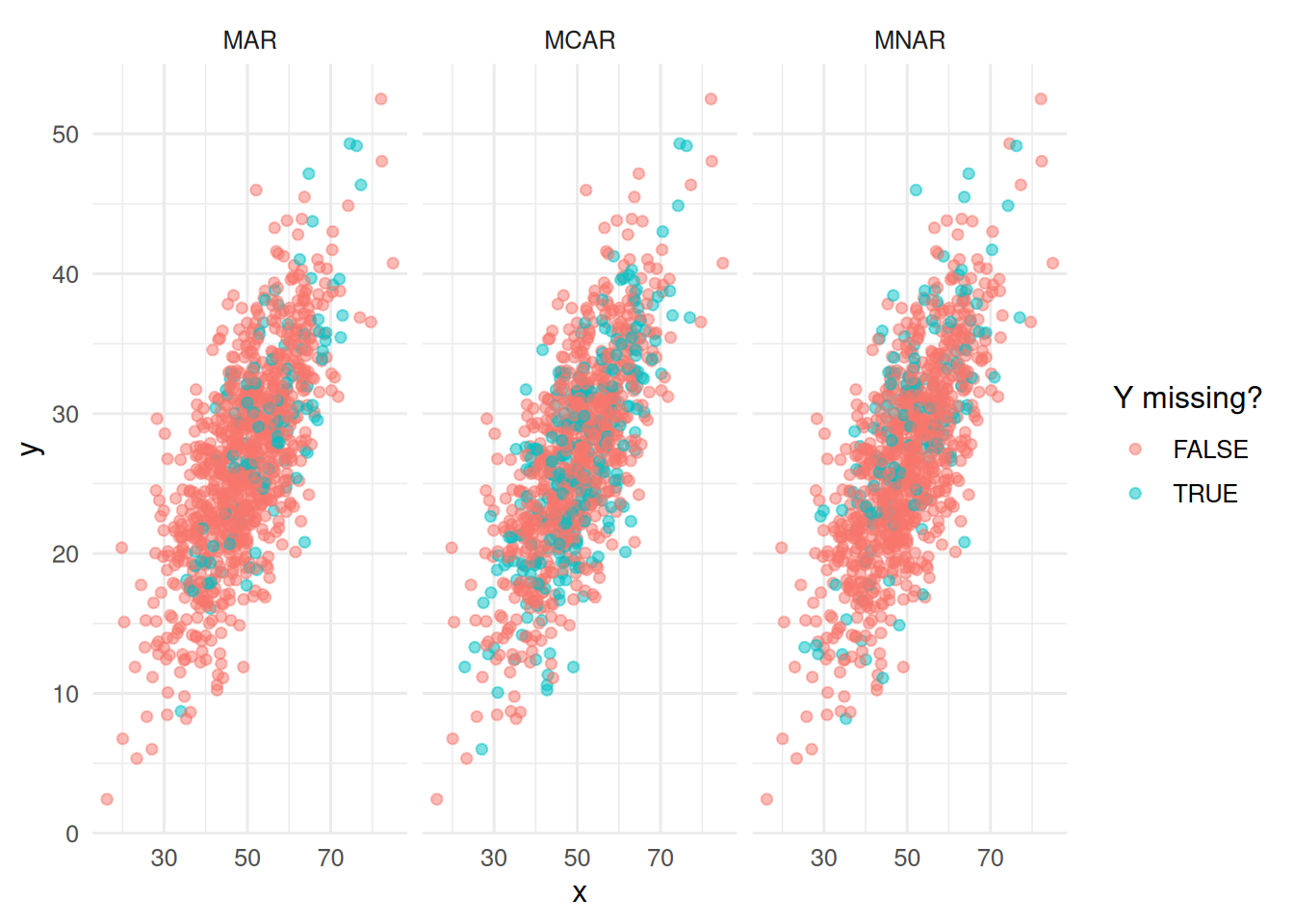
4. Conduct
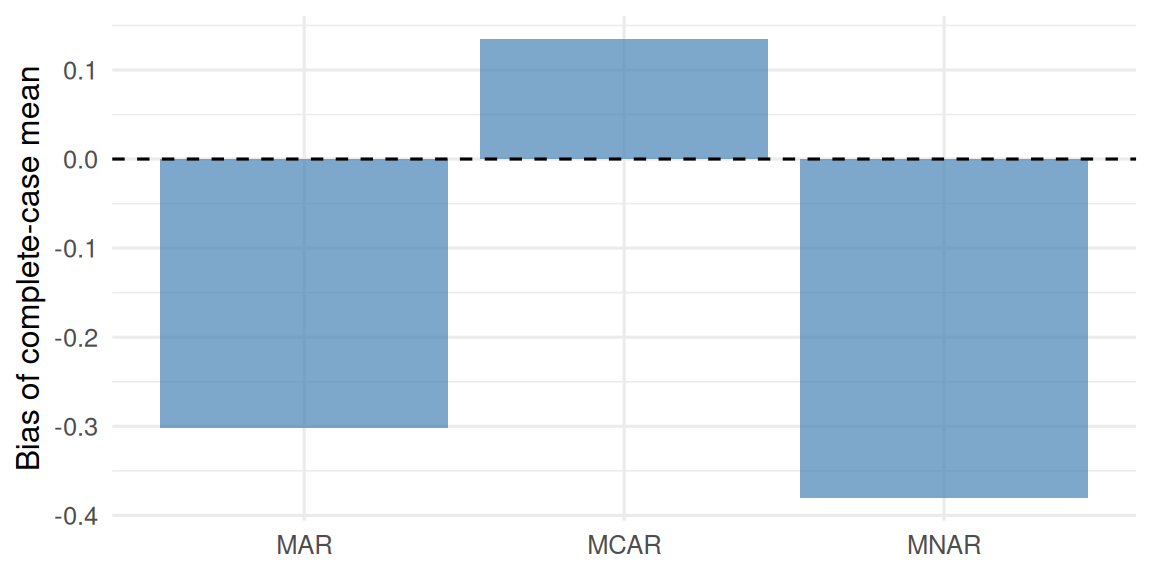
# A tibble: 3 × 5
mech truth cc bias pct_missing
<chr> <dbl> <dbl> <dbl> <dbl>
1 MAR 26.8 26.5 -0.301 12.7
2 MCAR 26.8 27.0 0.135 28.5
3 MNAR 26.8 26.5 -0.380 14.9