Week 2, Session 3 — Linear mixed models with lme4
Course 3 — #courses
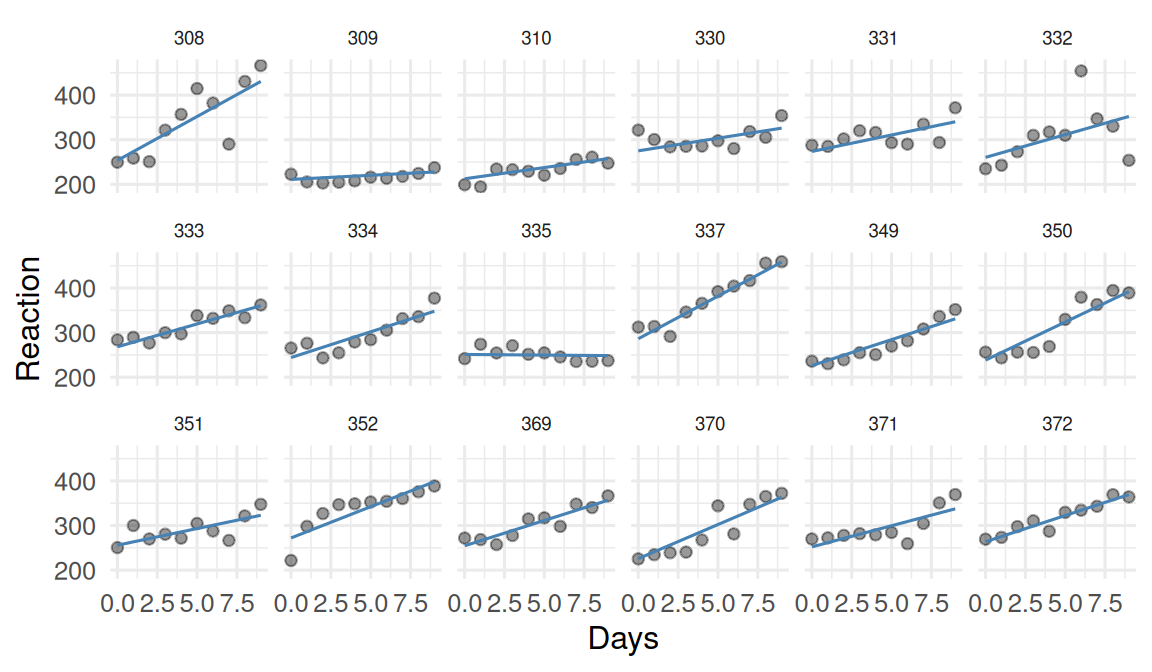
2. Visualise
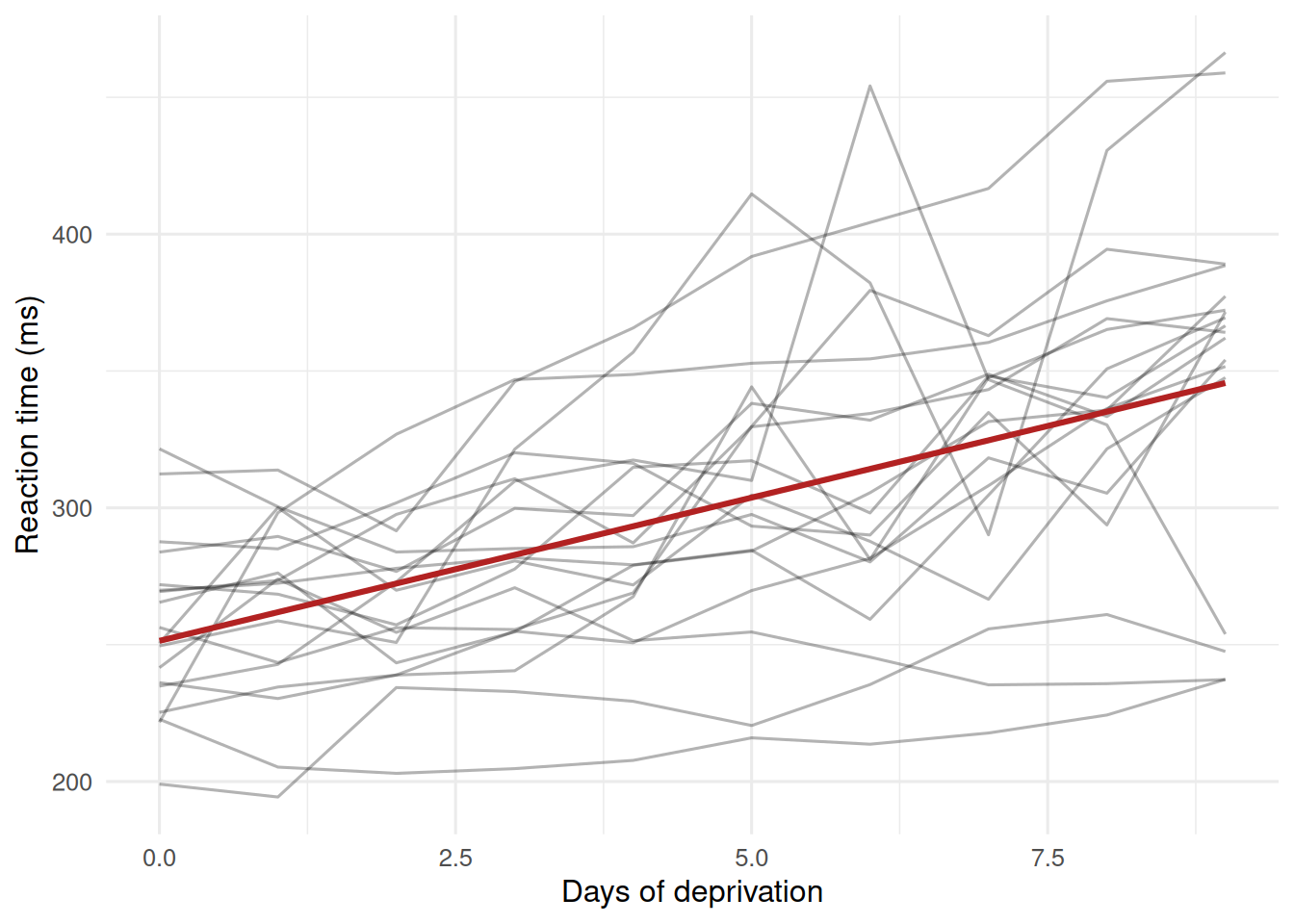
4. Conduct
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: Reaction ~ Days + (Days | Subject)
Data: sleepstudy
REML criterion at convergence: 1743.6
Scaled residuals:
Min 1Q Median 3Q Max
-3.9536 -0.4634 0.0231 0.4634 5.1793
Random effects:
Groups Name Variance Std.Dev. Corr
Subject (Intercept) 612.10 24.741
Days 35.07 5.922 0.07
Residual 654.94 25.592
Number of obs: 180, groups: Subject, 18
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 251.405 6.825 17.000 36.838 < 2e-16 ***
Days 10.467 1.546 17.000 6.771 3.26e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
Days -0.138Data: sleepstudy
Models:
ri: Reaction ~ Days + (1 | Subject)
rs: Reaction ~ Days + (Days | Subject)
npar AIC BIC logLik -2*log(L) Chisq Df Pr(>Chisq)
ri 4 1794.5 1807.2 -893.23 1786.5
rs 6 1755.6 1774.8 -871.81 1743.6 42.837 2 4.99e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Linear mixed model fit by maximum likelihood ['lmerModLmerTest']
Formula: Reaction ~ Days + (Days | Subject)
Data: sleepstudy
AIC BIC logLik -2*log(L) df.resid
1763.9393 1783.0971 -875.9697 1751.9393 174
Random effects:
Groups Name Std.Dev. Corr
Subject (Intercept) 23.780
Days 5.717 0.08
Residual 25.592
Number of obs: 180, groups: Subject, 18
Fixed Effects:
(Intercept) Days
251.41 10.47