Week 3, Session 4 — Propensity scores and IPTW
Course 3 — #courses
2. Visualise
n <- 1000
dat <- tibble(
age = rnorm(n, 60, 10),
sev = rnorm(n, 0, 1),
sex = rbinom(n, 1, 0.5)
) |>
mutate(ps = plogis(-1 + 0.04 * (age - 60) + 0.8 * sev + 0.3 * sex),
trt = rbinom(n, 1, ps),
y = 2 - 1.5 * trt + 0.05 * (age - 60) +
0.8 * sev + 0.3 * sex + rnorm(n, 0, 1))
ggplot(dat, aes(ps, fill = factor(trt))) +
geom_density(alpha = 0.5) +
labs(x = "Propensity score", y = "Density", fill = "Treated?")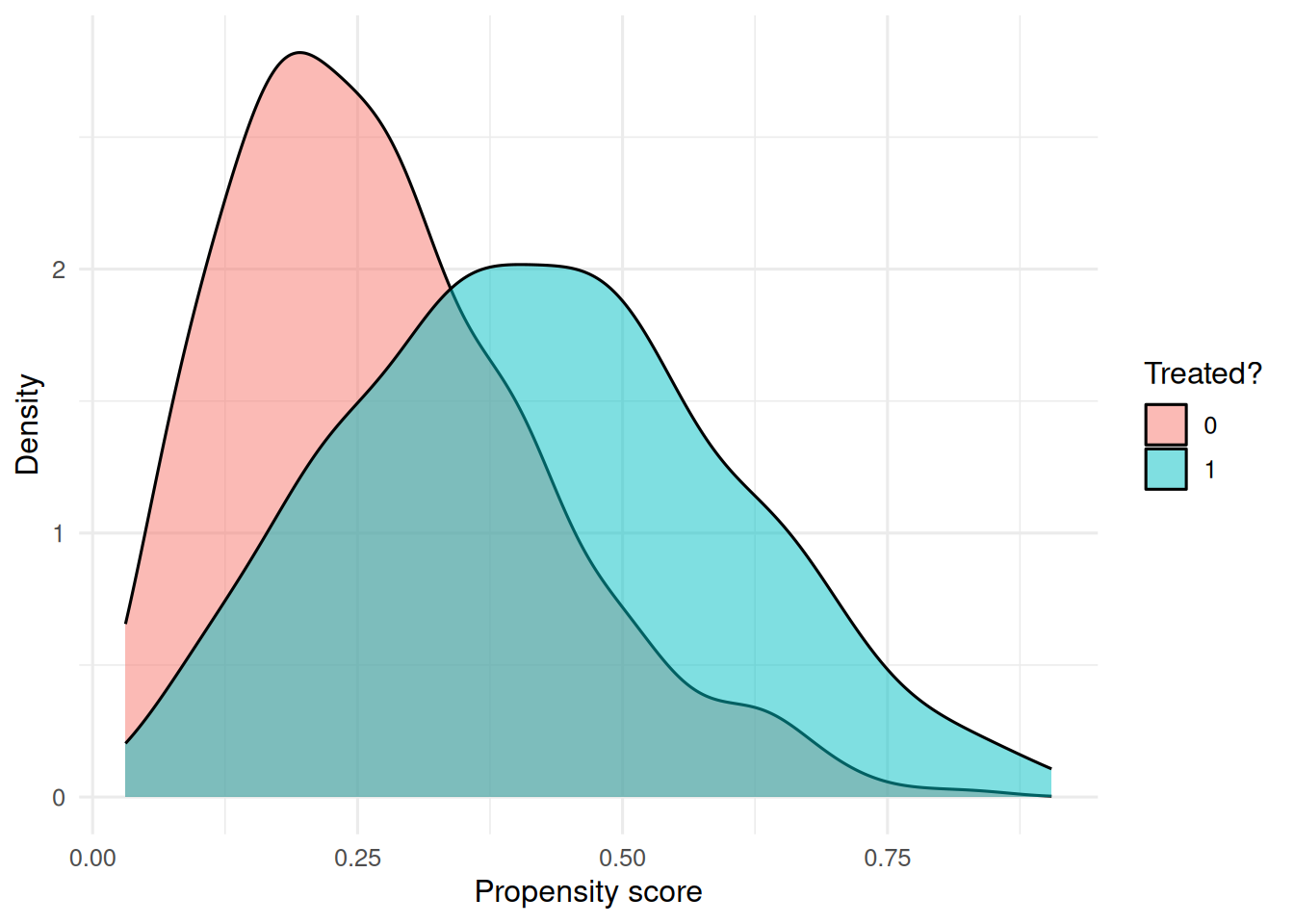
4. Conduct
trt
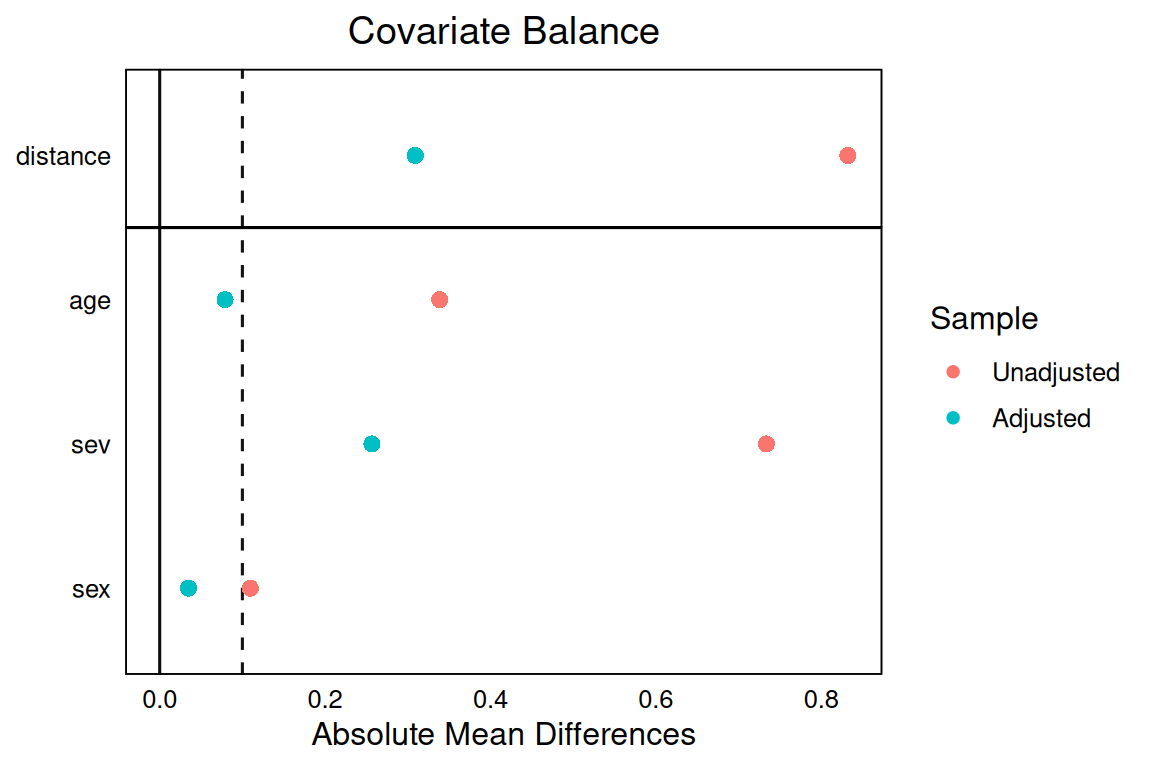
-1.502417 A `matchit` object
- method: 1:1 nearest neighbor matching without replacement
- distance: Propensity score
- estimated with logistic regression
- number of obs.: 1000 (original), 688 (matched)
- target estimand: ATT
- covariates: age, sev, sex trt
-1.281375 trt
-1.592614