Week 4, Session 1 — Systematic reviews and PRISMA
Course 3 — #courses
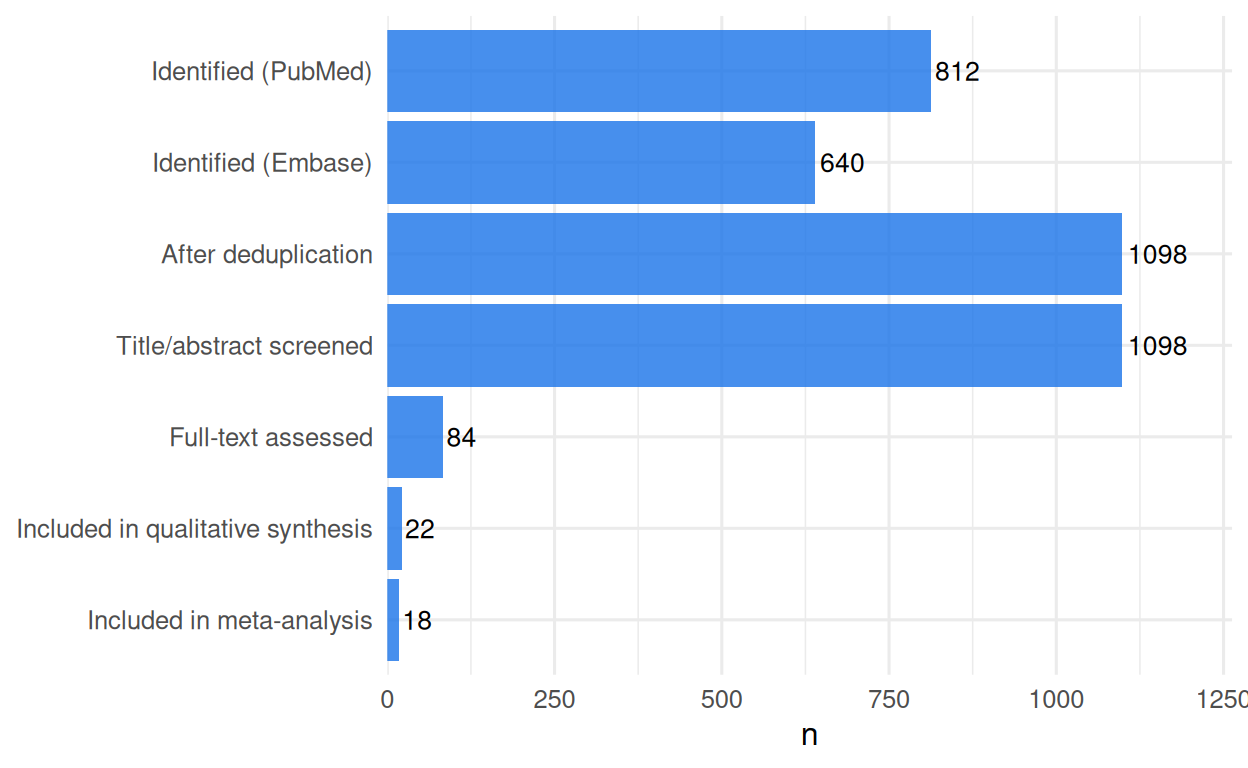
3. Execution — simulated screening counts
# A tibble: 7 × 2
stage n
<chr> <dbl>
1 Identified (PubMed) 812
2 Identified (Embase) 640
3 After deduplication 1098
4 Title/abstract screened 1098
5 Full-text assessed 84
6 Included in qualitative synthesis 22
7 Included in meta-analysis 18