Week 1, Session 4 — Clustering: k-means, hierarchical, model-based
Course 4 — #courses
2. Approach
Three Gaussian blobs in 5 dimensions with different sizes.
make_blob <- function(n, mu, sd = 1) matrix(rnorm(n * 5, 0, sd), n, 5) +
rep(mu, each = n)
X <- rbind(
make_blob(60, c(0, 0, 0, 0, 0)),
make_blob(40, c(3, 0, 0, 0, 0)),
make_blob(30, c(0, 3, 0, 0, 0))
)
true_lbl <- rep(c("A", "B", "C"), c(60, 40, 30))
pc <- prcomp(X)$x[, 1:2]
tibble(PC1 = pc[, 1], PC2 = pc[, 2], group = true_lbl) |>
ggplot(aes(PC1, PC2, colour = group)) + geom_point(alpha = 0.7)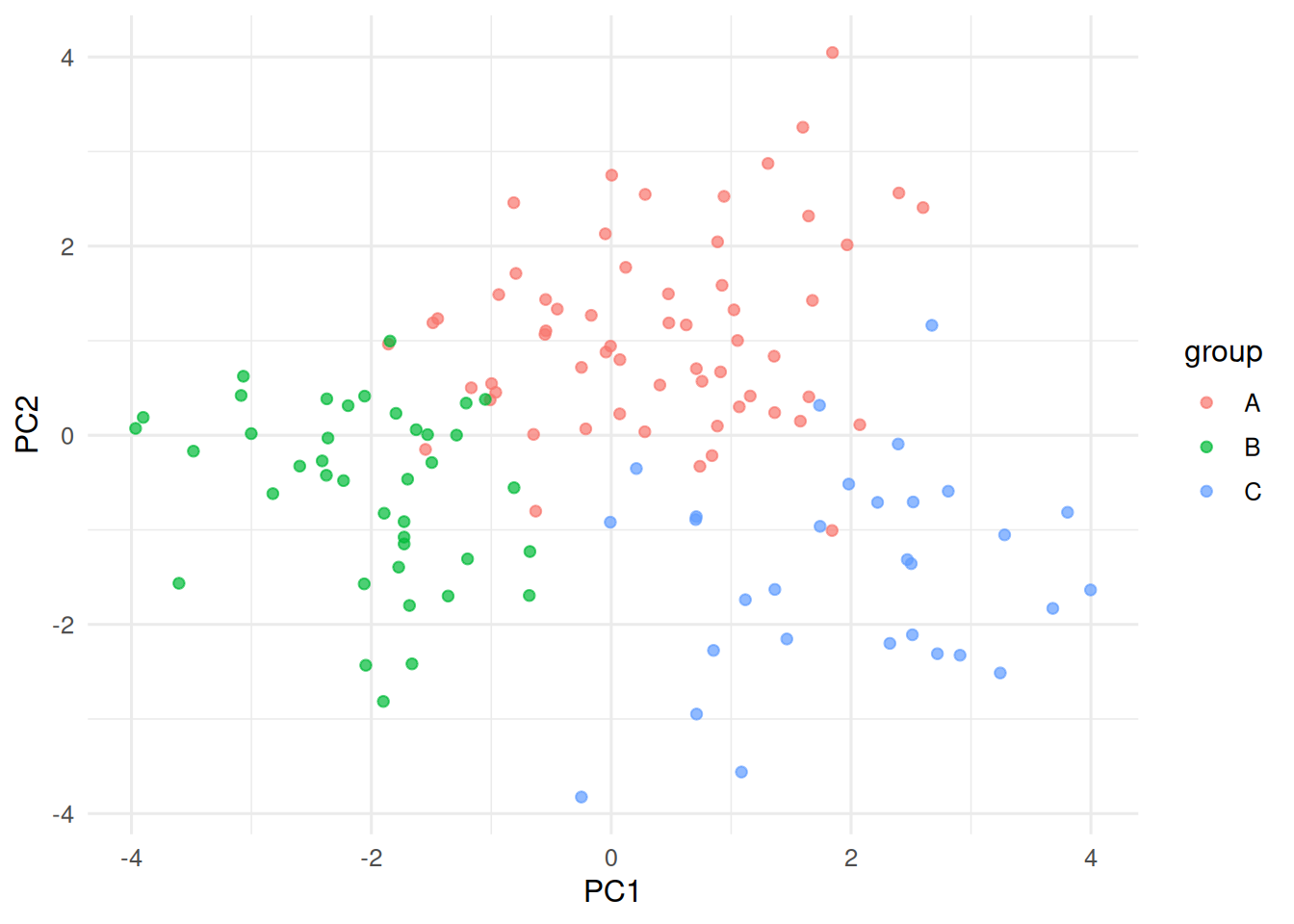
3. Execution
K-means with k sweep; silhouette.
wss <- sapply(2:8, function(k) kmeans(X, centers = k, nstart = 10)$tot.withinss)
sil <- sapply(2:8, function(k) {
km <- kmeans(X, centers = k, nstart = 10)
mean(silhouette(km$cluster, dist(X))[, 3])
})
tibble(k = 2:8, wss = wss, sil = sil) |>
pivot_longer(-k) |>
ggplot(aes(k, value)) + geom_line() + geom_point() +
facet_wrap(~ name, scales = "free_y")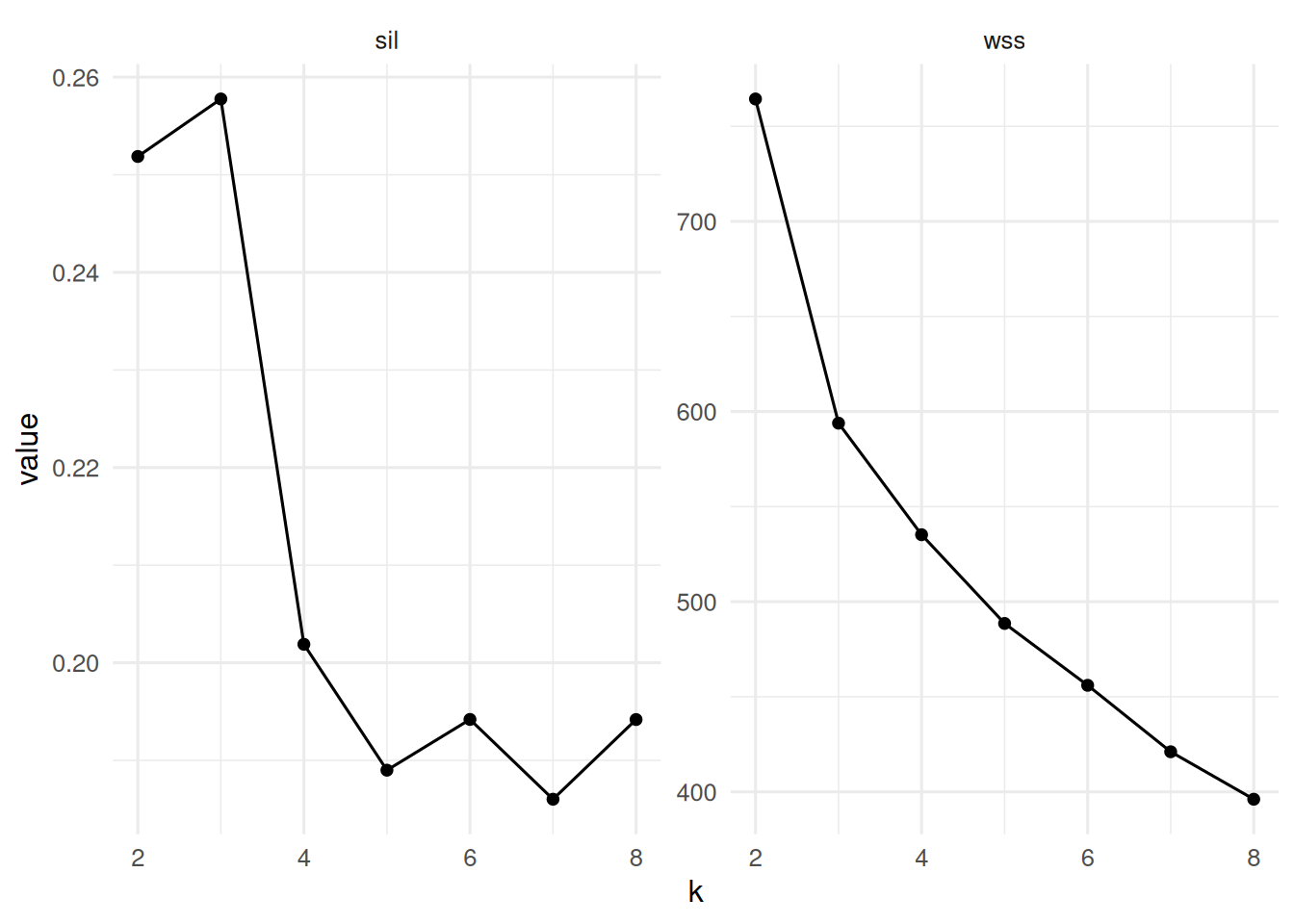
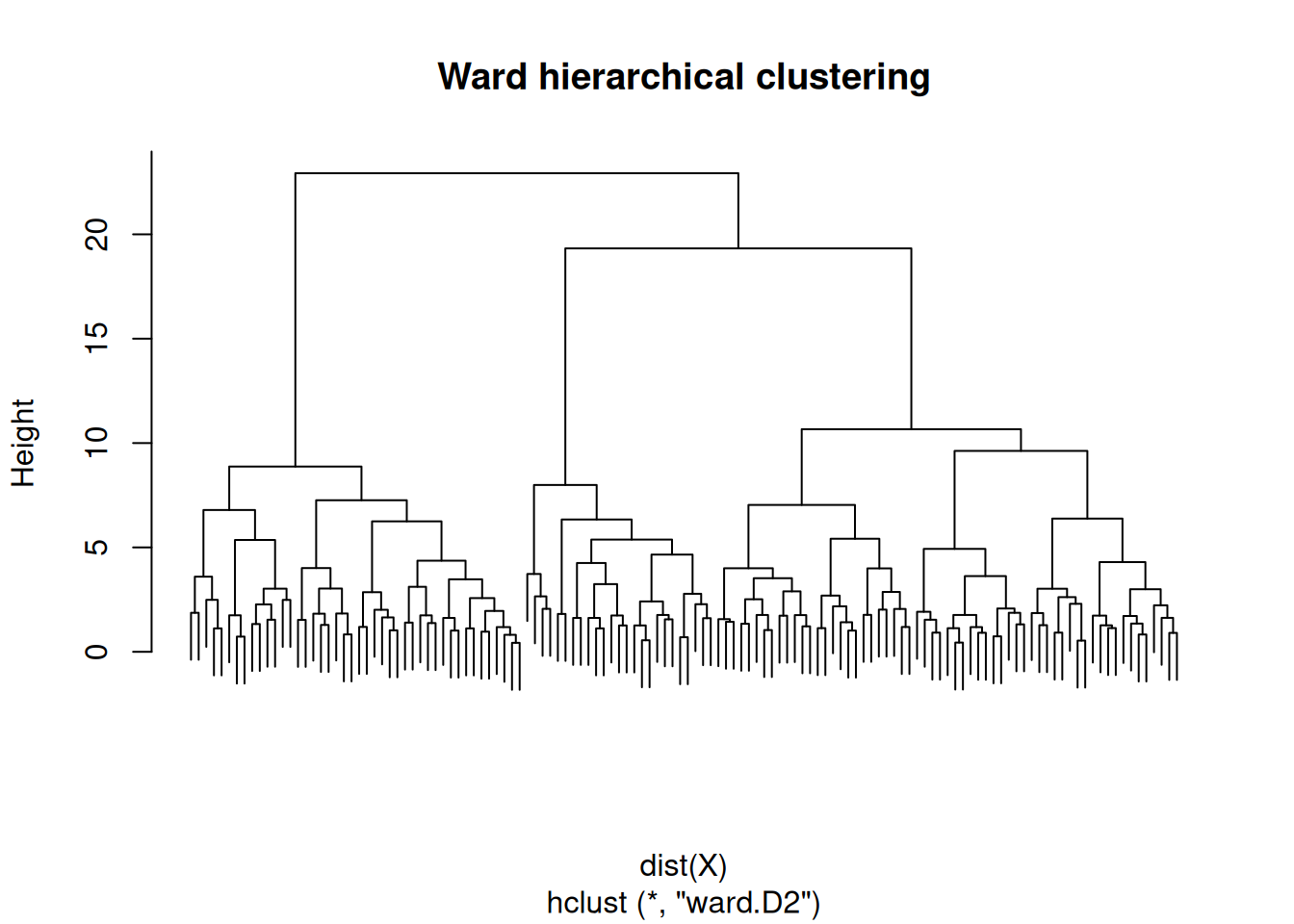
Hierarchical with Ward linkage.