Week 1, Session 5 — UMAP and t-SNE
Course 4 — #courses
3. Execution
emb_pca <- prcomp(X)$x[, 1:2]
emb_umap <- umap(X, n_neighbors = 15, min_dist = 0.1)
emb_tsne <- Rtsne(X, perplexity = 30, check_duplicates = FALSE)$Y
df <- bind_rows(
tibble(method = "PCA", x = emb_pca[, 1], y = emb_pca[, 2], lbl = lbl),
tibble(method = "UMAP", x = emb_umap[, 1], y = emb_umap[, 2], lbl = lbl),
tibble(method = "tSNE", x = emb_tsne[, 1], y = emb_tsne[, 2], lbl = lbl)
)
ggplot(df, aes(x, y, colour = lbl)) +
geom_point(alpha = 0.7, size = 0.8) +
facet_wrap(~ method, scales = "free") +
labs(x = NULL, y = NULL)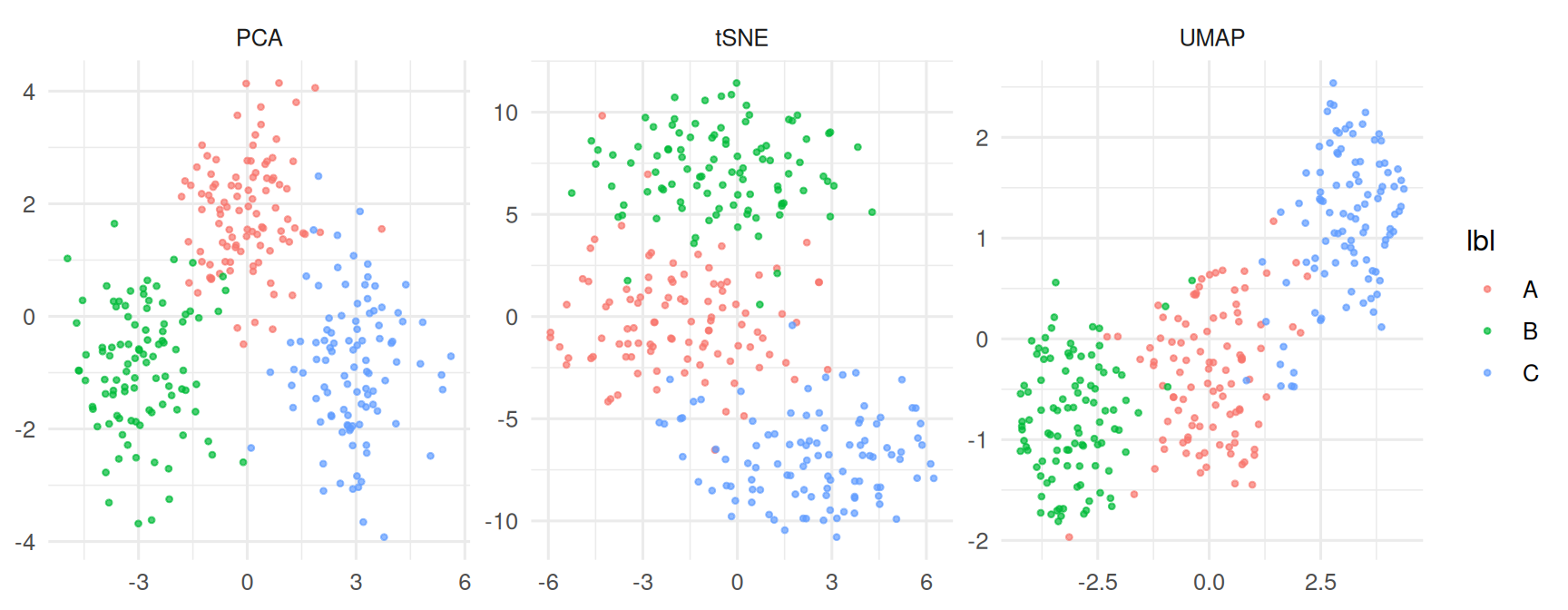
4. Check
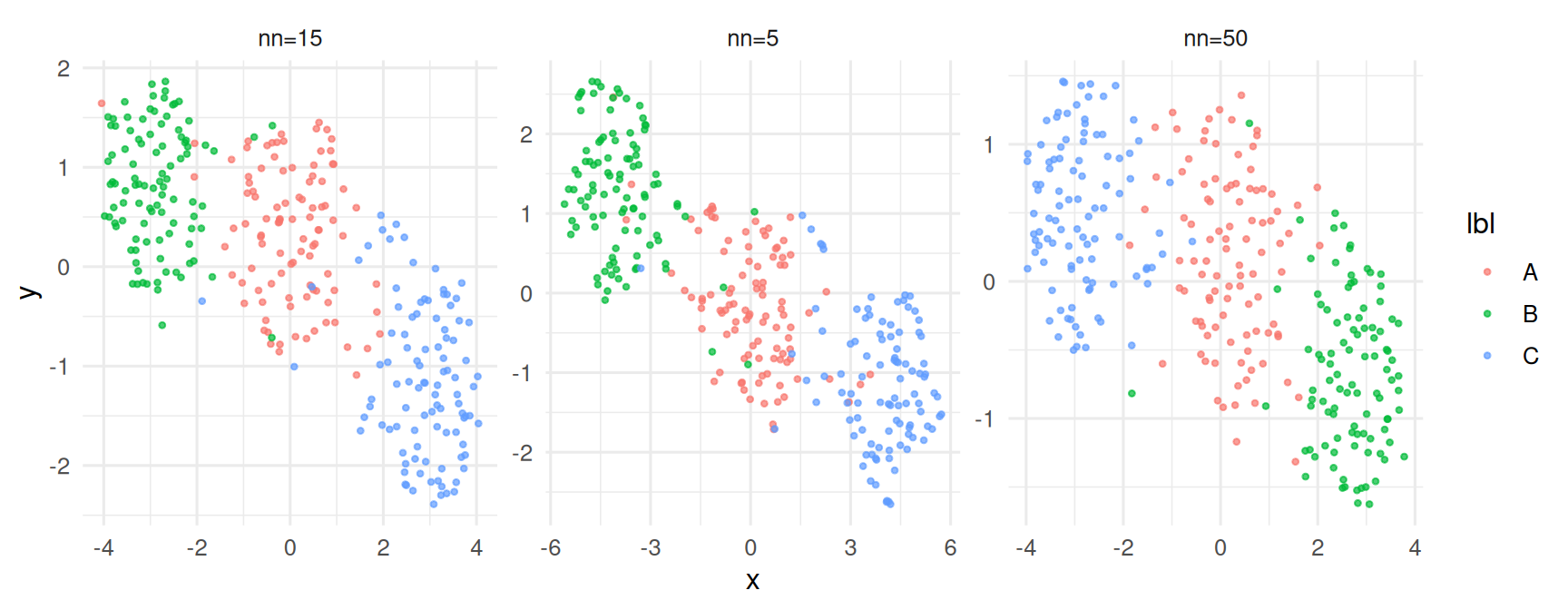
Sensitivity to n_neighbors.