Week 2, Session 1 — Trees, random forests, gradient boosting
Course 4 — #courses
2. Approach
4. Check
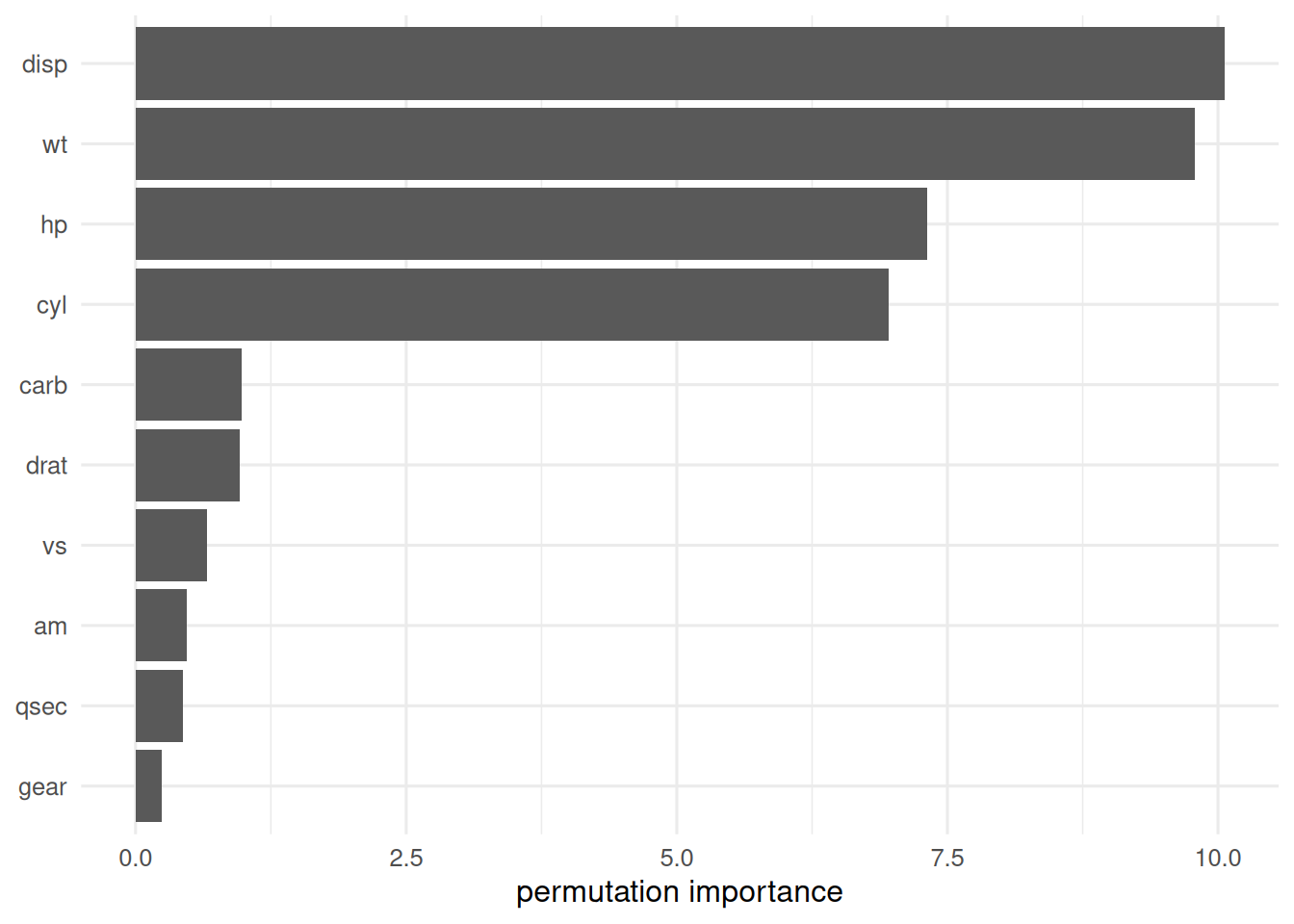
Honest error: CV for the tree and xgboost, OOB for ranger.
K <- 5
folds <- sample(rep(1:K, length.out = nrow(d)))
mse <- function(y, yhat) mean((y - yhat)^2)
get_err <- function() {
err_tree <- err_rf <- err_xg <- numeric(K)
for (k in 1:K) {
tr <- folds != k; te <- folds == k
f_tr <- d[tr, ]; f_te <- d[te, ]
t1 <- rpart(mpg ~ ., data = f_tr, cp = 0.01)
r1 <- ranger(mpg ~ ., data = f_tr, num.trees = 500)
x1 <- xgboost(
data = as.matrix(f_tr[, -1]), label = f_tr$mpg,
nrounds = 100, eta = 0.05, max_depth = 3,
objective = "reg:squarederror", verbose = 0
)
err_tree[k] <- mse(f_te$mpg, predict(t1, f_te))
err_rf[k] <- mse(f_te$mpg, predict(r1, f_te)$predictions)
err_xg[k] <- mse(f_te$mpg, predict(x1, as.matrix(f_te[, -1])))
}
c(tree = mean(err_tree), rf = mean(err_rf), xgb = mean(err_xg))
}
errs <- get_err()
errs tree rf xgb
13.900260 4.814310 7.995655