Week 2, Session 3 — Tabular neural networks with torch
Course 4 — #courses
2. Approach
3. Execution
Base-R gradient descent on the same problem.
w <- rep(0, p); lr <- 0.01
losses <- numeric(200)
for (step in 1:200) {
yhat <- X %*% w
resid <- as.numeric(y - yhat)
grad <- -2 * t(X) %*% resid / n
w <- w - lr * grad
losses[step] <- mean(resid^2)
}
tibble(step = 1:200, loss = losses) |>
ggplot(aes(step, loss)) + geom_line() +
labs(x = "iteration", y = "mean squared error")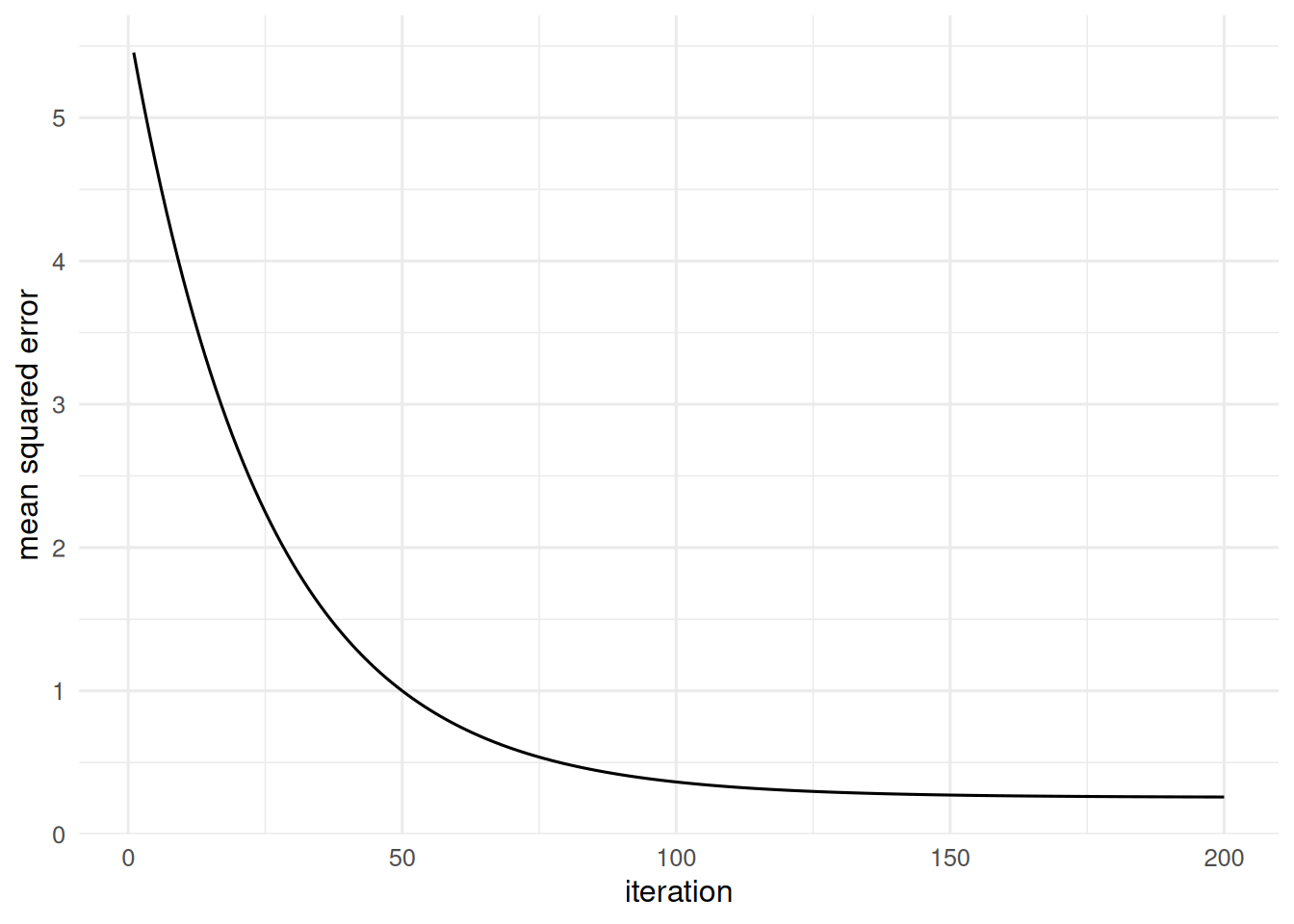
The equivalent torch code.
library(torch)
x_t <- torch_tensor(X, dtype = torch_float())
y_t <- torch_tensor(matrix(y, ncol = 1), dtype = torch_float())
net <- nn_sequential(
nn_linear(p, 16), nn_relu(),
nn_linear(16, 1)
)
optimizer <- optim_adam(net$parameters, lr = 1e-2)
loss_fn <- nn_mse_loss()
for (epoch in 1:200) {
optimizer$zero_grad()
pred <- net(x_t)
loss <- loss_fn(pred, y_t)
loss$backward()
optimizer$step()
}4. Check
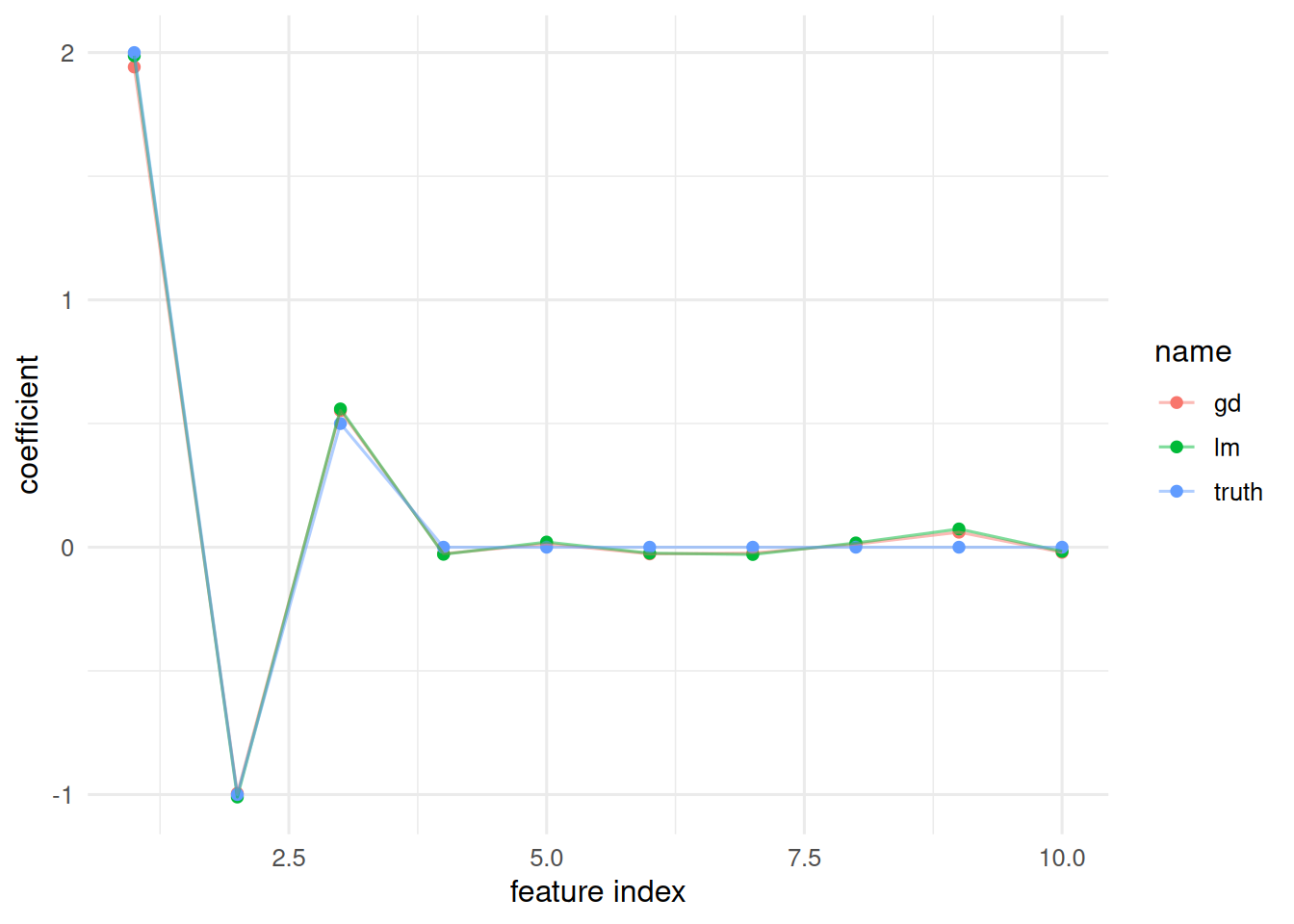
Compare our gradient-descent weights against the OLS solution.