Week 3, Session 2 — brms / Stan, LOO, hierarchical models
Course 4 — #courses
2. Approach
Simulate 20 centres with varying mean outcomes and varying dose effects.
n_centre <- 20; per_centre <- 15
centre <- rep(seq_len(n_centre), each = per_centre)
alpha0 <- rnorm(n_centre, 0, 1)
beta0 <- rnorm(n_centre, 0.5, 0.3)
dose <- rnorm(n_centre * per_centre)
y <- alpha0[centre] + beta0[centre] * dose + rnorm(n_centre * per_centre, 0, 0.7)
d <- tibble(y = y, dose = dose, centre = factor(centre))
ggplot(d, aes(dose, y, colour = centre)) +
geom_point(alpha = 0.5) + geom_smooth(method = "lm", se = FALSE) +
theme(legend.position = "none")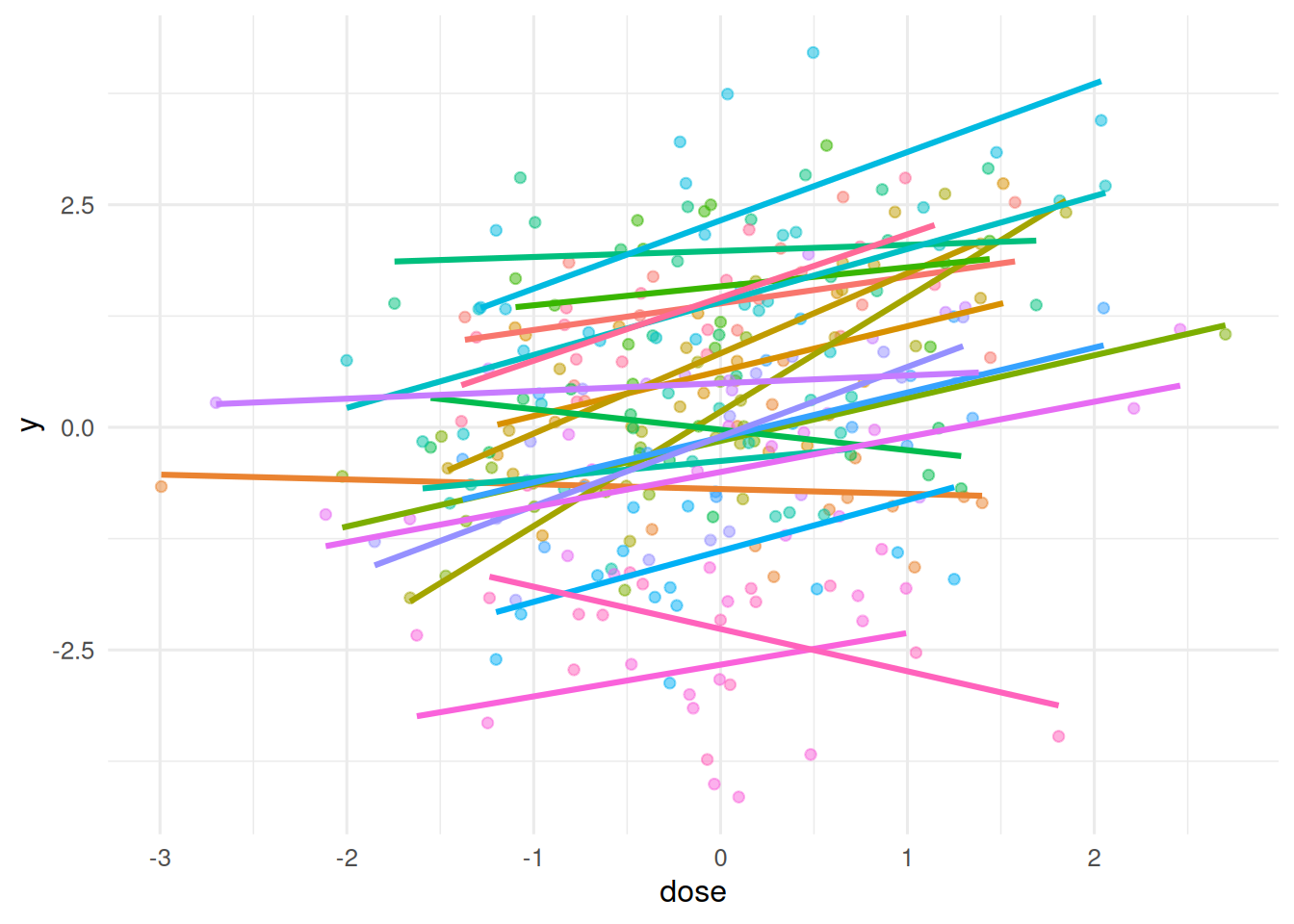
3. Execution
A classical lmer random-intercept-and-slope fit as a stand-in we can run.
Groups Name Std.Dev. Corr
centre (Intercept) 1.31121
dose 0.34365 0.382
Residual 0.71603 Data: d
Models:
fit_lmer_ri: y ~ dose + (1 | centre)
fit_lmer_rs: y ~ dose + (dose | centre)
npar AIC BIC logLik -2*log(L) Chisq Df Pr(>Chisq)
fit_lmer_ri 4 781.48 796.30 -386.74 773.48
fit_lmer_rs 6 763.66 785.88 -375.83 751.66 21.823 2 1.824e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Prior predictive simulation (frequentist-style) for the Bayesian counterpart we are about to sketch.
prior_sim <- replicate(20, {
a <- rnorm(1, 0, 1); b <- rnorm(1, 0, 1); sd_a <- abs(rnorm(1, 0, 1))
a + b * dose + rnorm(length(dose), 0, sd_a)
})
ggplot(tibble(y = as.numeric(prior_sim)), aes(y)) +
geom_histogram(bins = 40, fill = "grey60", colour = "white") +
labs(x = "y drawn under priors only", y = "count")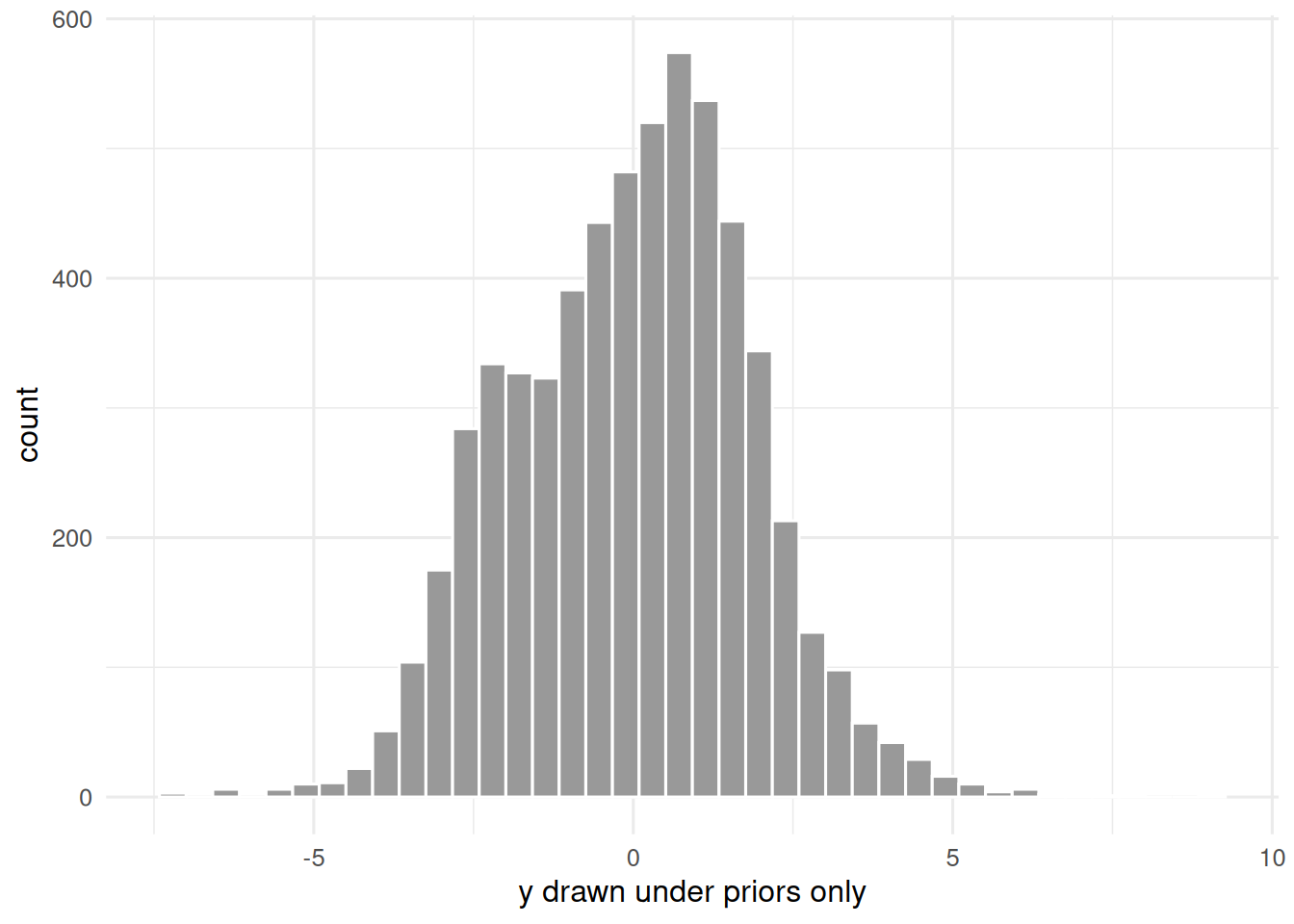
The brms counterpart.
library(brms)
priors <- c(
prior(normal(0, 2), class = "Intercept"),
prior(normal(0, 1), class = "b"),
prior(exponential(1), class = "sd"),
prior(exponential(1), class = "sigma")
)
m_ri <- brm(y ~ dose + (1 | centre), data = d,
prior = priors, chains = 2, iter = 2000, refresh = 0)
m_rs <- brm(y ~ dose + (dose | centre), data = d,
prior = priors, chains = 2, iter = 2000, refresh = 0)
loo_compare(loo(m_ri), loo(m_rs))