Week 3, Session 4 — Survival ML (random survival forest, DeepSurv)
Course 4 — #courses
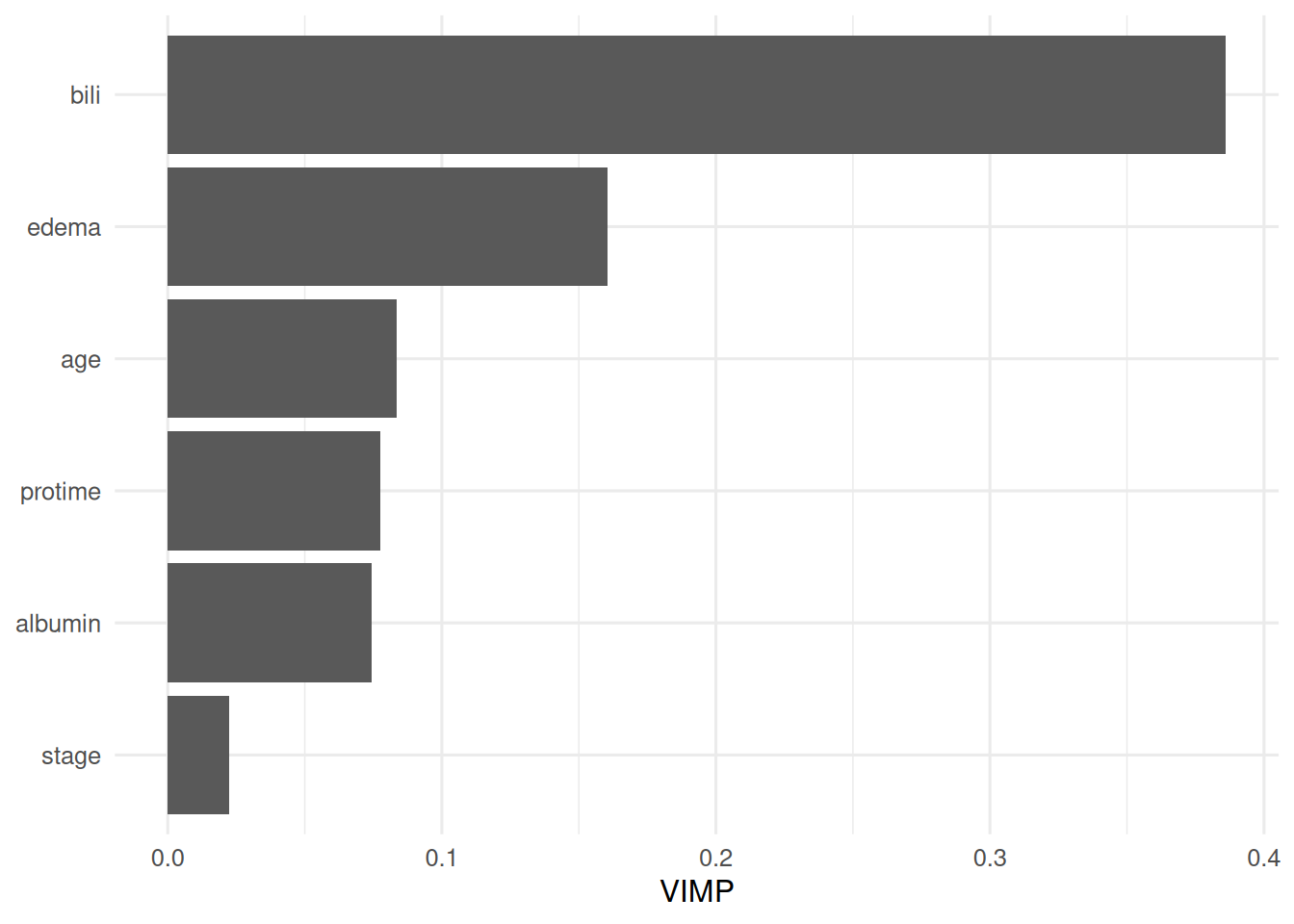
2. Approach
d <- survival::pbc |>
as_tibble() |>
drop_na(bili, albumin, age, edema, protime, stage) |>
mutate(status = ifelse(status == 2, 1, 0))
ggplot(d, aes(time / 365.25, fill = factor(status))) +
geom_histogram(bins = 30, alpha = 0.7, position = "identity") +
labs(x = "follow-up (years)", y = "count", fill = "event")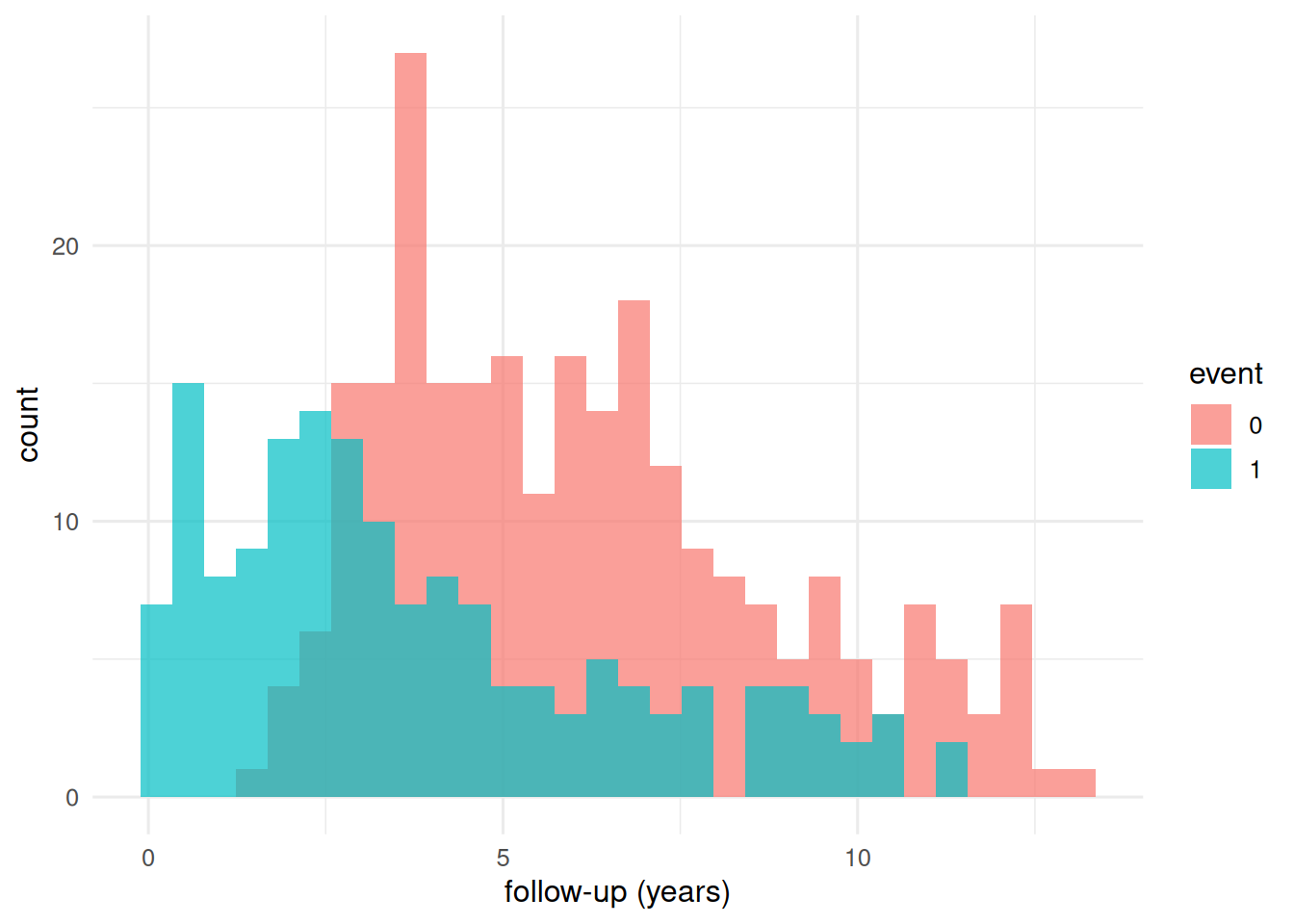
3. Execution
Sample size: 410
Number of deaths: 156
Number of trees: 500
Forest terminal node size: 15
Average no. of terminal nodes: 19.574
No. of variables tried at each split: 3
Total no. of variables: 6
Resampling used to grow trees: swor
Resample size used to grow trees: 259
Analysis: RSF
Family: surv
Splitting rule: logrank *random*
Number of random split points: 10
(OOB) CRPS: 505.07481851
(OOB) standardized CRPS: 0.12051415
(OOB) Requested performance error: 0.18039411