Workflow labs use the variant template: Goal → Approach → Execution → Check → Report.
Learning objectives
Walk through the Seurat pipeline: QC, normalisation, feature selection, PCA, neighbour graph, clustering, UMAP.
Describe why scRNA-seq counts need different handling from bulk counts.
Produce a small analogous pipeline in base R with simulated cells and the uwot UMAP.
Prerequisites
UMAP from Week 1 Session 5; RNA-seq from Session 1.
Background
Single-cell RNA-seq measures gene expression in thousands of cells simultaneously, producing a sparse, noisy, zero-inflated matrix. Clustering and cell-type annotation are exploratory steps that require a chain of careful preprocessing: drop empty droplets, normalise library size, select variable genes, reduce to principal components, build a nearest-neighbour graph, cluster on the graph, embed with UMAP.
Seurat is the dominant R toolkit for this pipeline. Every step has alternatives — SCTransform vs NormalizeData, Louvain vs Leiden clustering, Harmony for batch correction — and each choice changes the resulting partition. The good reflex is to run the same pipeline twice with a perturbed parameter and check that the biology survives.
Seurat is not on CRAN and its installation is non-trivial in a rendering environment. We sketch the pipeline with #| eval: false and run an analogous, tiny base-R + uwot pipeline on a simulated cell × gene matrix so the reasoning is visible in every render.
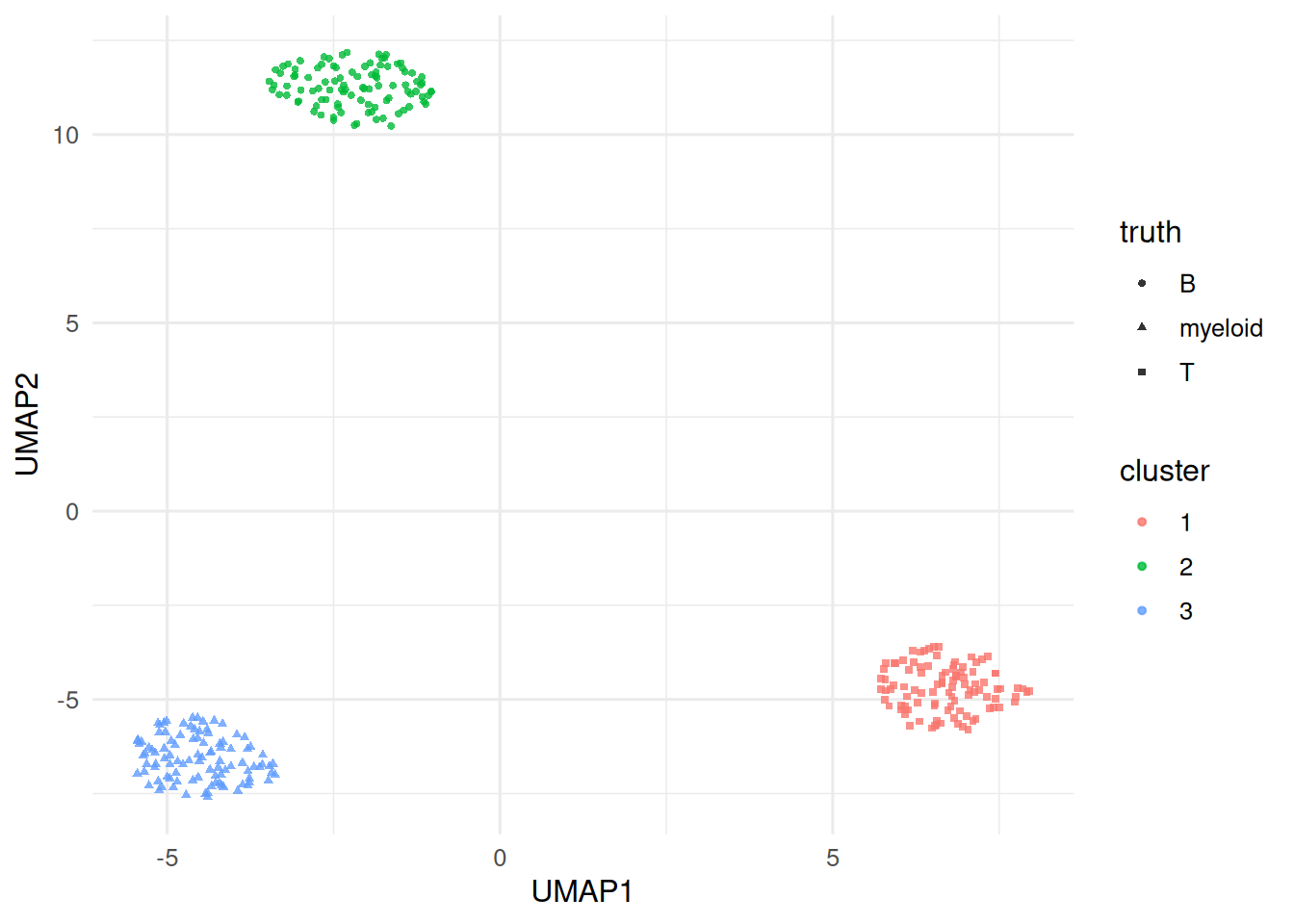
truth
cluster B myeloid T
1 0 0 100
2 100 0 0
3 0 100 0
5. Report
On a simulated 300-cell × 500-gene dataset with three cell types, a small pipeline (log normalisation, top-100 variable genes, 10 PCs, UMAP, k-means) recovered the three types with high agreement. The same reasoning — preprocess, reduce, graph, cluster, embed — underlies the Seurat pipeline sketched in the accompanying code.
On a real dataset the critical choices are the normalisation (SCTransform vs NormalizeData), the number of PCs (elbow or JackStraw), and the clustering resolution. Perturb each and confirm that the biological conclusions do not.
Common pitfalls
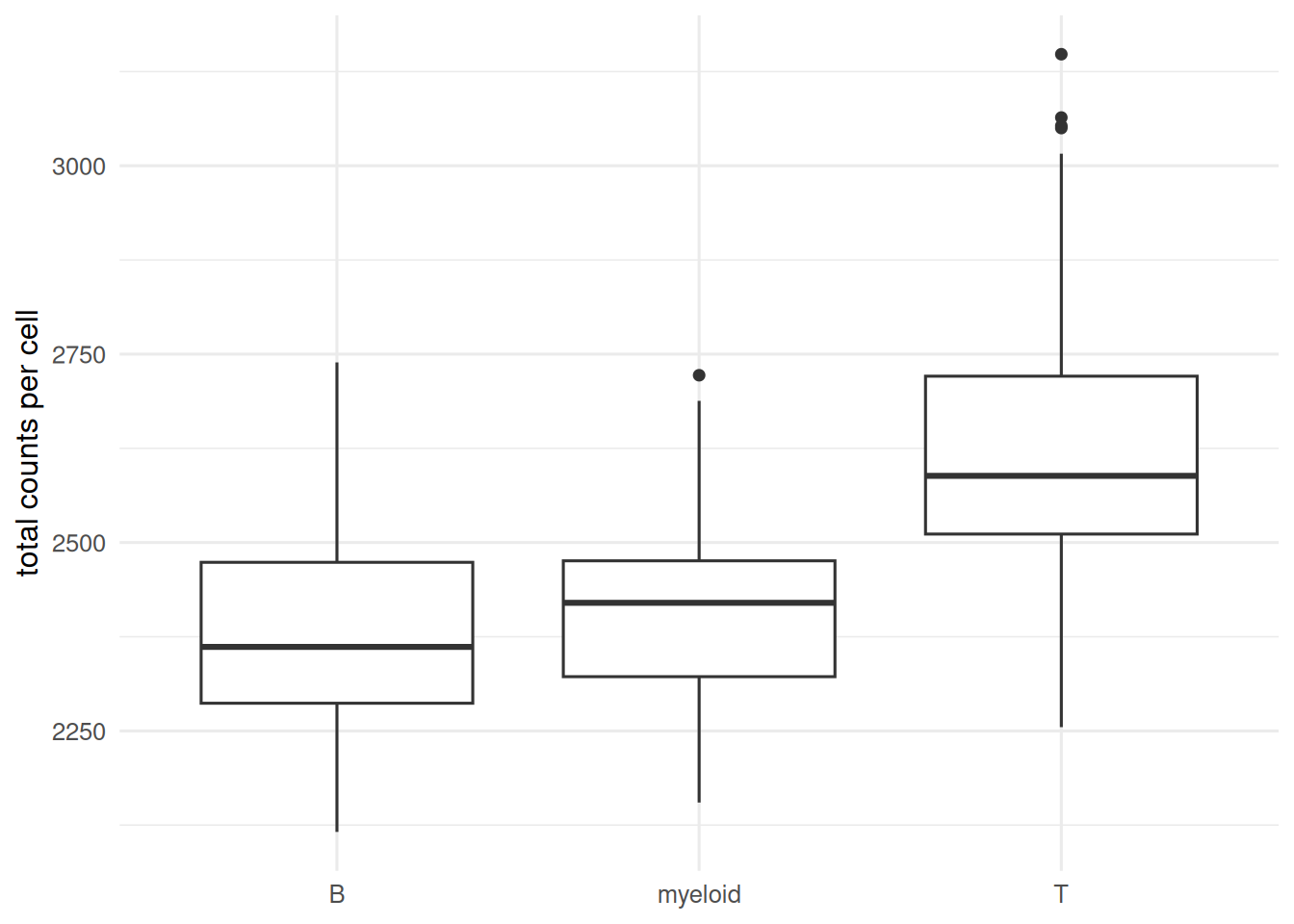
Clustering before QC; apoptotic cells and empty droplets cluster together.
Forgetting that UMAP distances are not biological distances.
Using marker genes from a tutorial on a different tissue for cell-type annotation.
Further reading
Stuart T et al. (2019), Comprehensive integration of single-cell data.
Luecken MD, Theis FJ (2019), Current best practices in single-cell RNA-seq analysis: a tutorial.